 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Much Can I Trust You? -- Quantifying Uncertainties in Explaining Neural Networks
Paper and Code

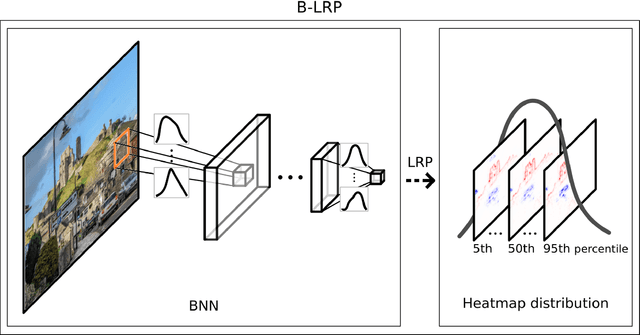
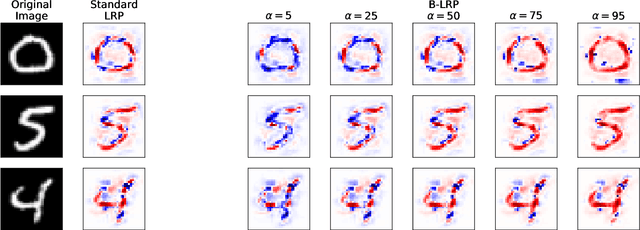

Explainable AI (XAI) aims to provide interpretations for predictions made by learning machines, such as deep neural networks, in order to make the machines more transparent for the user and furthermore trustworthy also for applications in e.g. safety-critical areas. So far, however, no methods for quantifying uncertainties of explanations have been conceived, which is problematic in domains where a high confidence in explanations is a prerequisite. We therefore contribute by proposing a new framework that allows to convert any arbitrary explanation method for neural networks into an explanation method for Bayesian neural networks, with an in-built modeling of uncertainties. Within the Bayesian framework a network's weights follow a distribution that extends standard single explanation scores and heatmaps to distributions thereof, in this manner translating the intrinsic network model uncertainties into a quantification of explanation uncertainties. This allows us for the first time to carve out uncertainties associated with a model explanation and subsequently gauge the appropriate level of explanation confidence for a user (using percentiles). We demonstrate the effectiveness and usefulness of our approach extensively in various experiments, both qualitatively and quantitatively.