 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow good are Large Language Models on African Languages?
Paper and Code
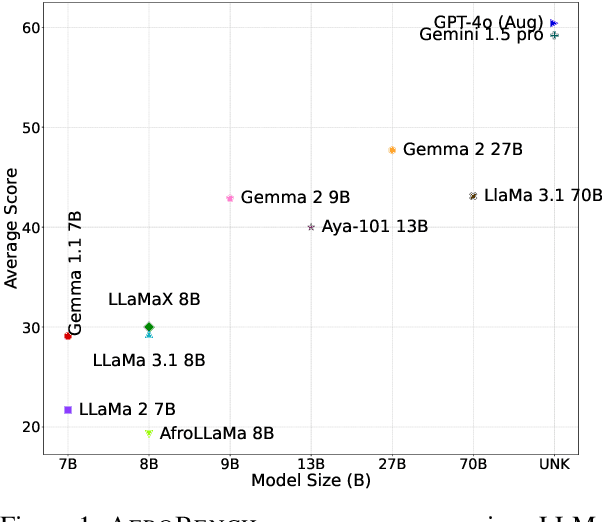



Recent advancements in natural language processing have led to the proliferation of large language models (LLMs). These models have been shown to yield good performance, using in-context learning, even on unseen tasks and languages. Additionally, they have been widely adopted as language-model-as-a-service commercial APIs like GPT-4 API. However, their performance on African languages is largely unknown. We present an analysis of three popular large language models (mT0, LLaMa 2, and GPT-4) on five tasks (news topic classification, sentiment classification, machine translation, question answering, and named entity recognition) across 30 African languages, spanning different language families and geographical regions. Our results suggest that all LLMs produce below-par performance on African languages, and there is a large gap in performance compared to high-resource languages like English most tasks. We find that GPT-4 has an average or impressive performance on classification tasks but very poor results on generative tasks like machine translation. Surprisingly, we find that mT0 had the best overall on cross-lingual QA, better than the state-of-the-art supervised model (i.e. fine-tuned mT5) and GPT-4 on African languages. Overall, LLaMa 2 records the worst performance due to its limited multilingual capabilities and English-centric pre-training corpus. In general, our findings present a call-to-action to ensure African languages are well represented in large language models, given their growing popularity.