 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Does Momentum Help Frank Wolfe?
Paper and Code
Jun 19, 2020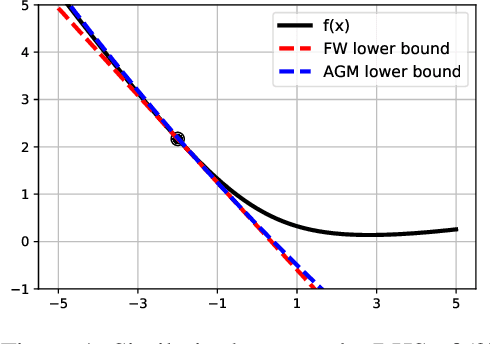

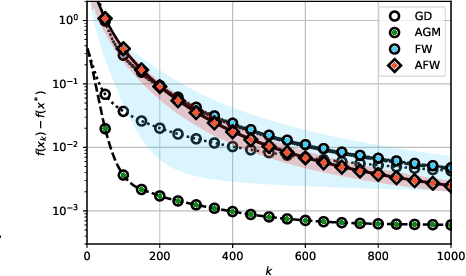
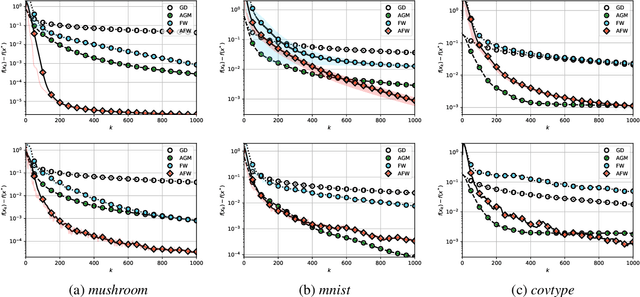
We unveil the connections between Frank Wolfe (FW) type algorithms and the momentum in Accelerated Gradient Methods (AGM). On the negative side, these connections illustrate why momentum is unlikely to be effective for FW type algorithms. The encouraging message behind this link, on the other hand, is that momentum is useful for FW on a class of problems. In particular, we prove that a momentum variant of FW, that we term accelerated Frank Wolfe (AFW), converges with a faster rate $\tilde{\cal O}(\frac{1}{k^2})$ on certain constraint sets despite the same ${\cal O}(\frac{1}{k})$ rate as FW on general cases. Given the possible acceleration of AFW at almost no extra cost, it is thus a competitive alternative to FW. Numerical experiments on benchmarked machine learning tasks further validate our theoretical findings.