 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Deep Neural Networks Learn Compositional Data: The Random Hierarchy Model
Paper and Code
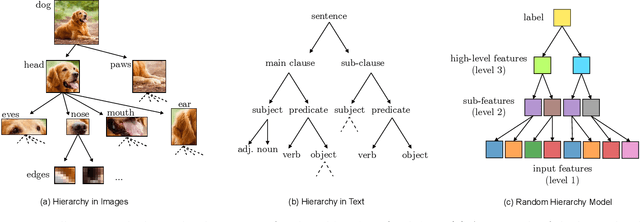
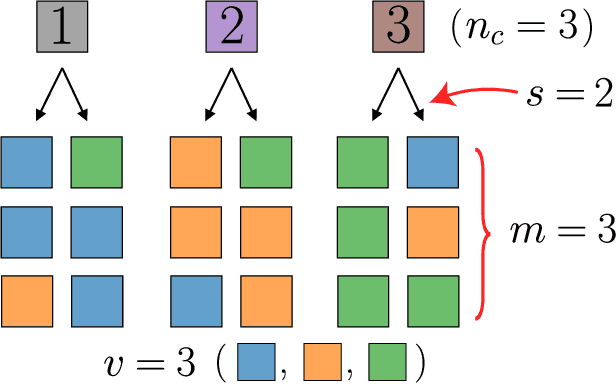
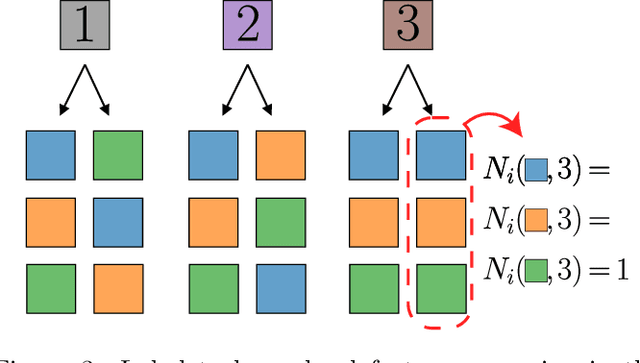
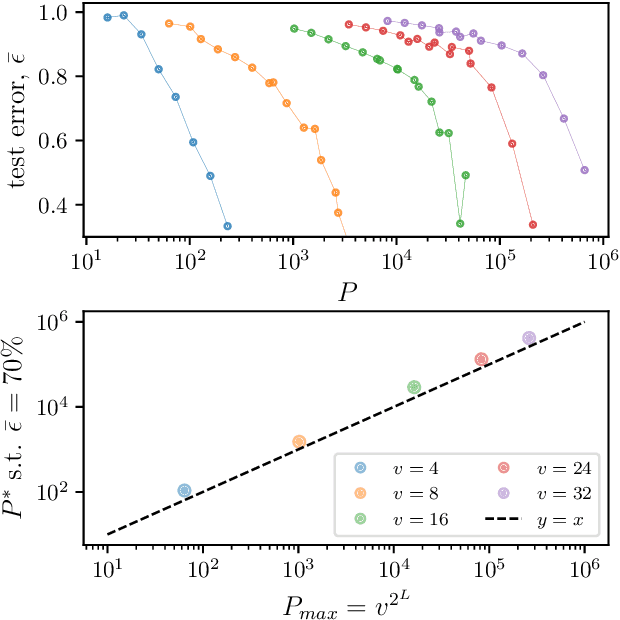
Learning generic high-dimensional tasks is notably hard, as it requires a number of training data exponential in the dimension. Yet, deep convolutional neural networks (CNNs) have shown remarkable success in overcoming this challenge. A popular hypothesis is that learnable tasks are highly structured and that CNNs leverage this structure to build a low-dimensional representation of the data. However, little is known about how much training data they require, and how this number depends on the data structure. This paper answers this question for a simple classification task that seeks to capture relevant aspects of real data: the Random Hierarchy Model. In this model, each of the $n_c$ classes corresponds to $m$ synonymic compositions of high-level features, which are in turn composed of sub-features through an iterative process repeated $L$ times. We find that the number of training data $P^*$ required by deep CNNs to learn this task (i) grows asymptotically as $n_c m^L$, which is only polynomial in the input dimensionality; (ii) coincides with the training set size such that the representation of a trained network becomes invariant to exchanges of synonyms; (iii) corresponds to the number of data at which the correlations between low-level features and classes become detectable. Overall, our results indicate how deep CNNs can overcome the curse of dimensionality by building invariant representations, and provide an estimate of the number of data required to learn a task based on its hierarchically compositional structure.