 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHistogram Transform Ensembles for Large-scale Regression
Paper and Code
Dec 08, 2019
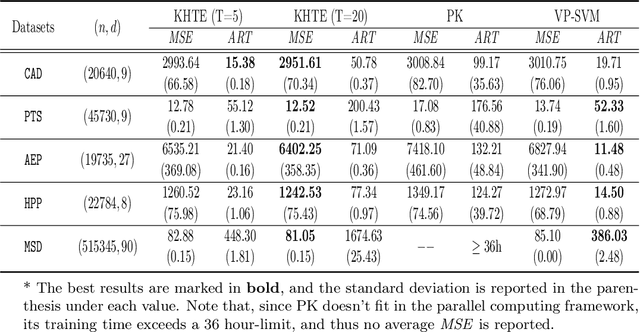
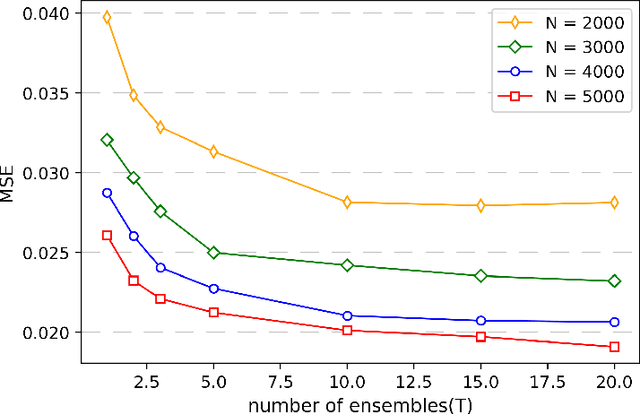
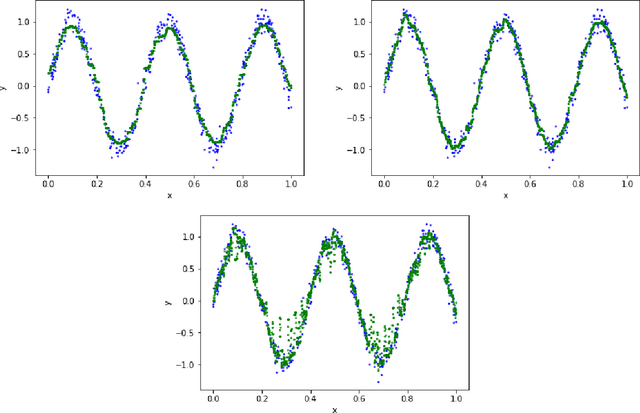
We propose a novel algorithm for large-scale regression problems named histogram transform ensembles (HTE), composed of random rotations, stretchings, and translations. First of all, we investigate the theoretical properties of HTE when the regression function lies in the H\"{o}lder space $C^{k,\alpha}$, $k \in \mathbb{N}_0$, $\alpha \in (0,1]$. In the case that $k=0, 1$, we adopt the constant regressors and develop the na\"{i}ve histogram transforms (NHT). Within the space $C^{0,\alpha}$, although almost optimal convergence rates can be derived for both single and ensemble NHT, we fail to show the benefits of ensembles over single estimators theoretically. In contrast, in the subspace $C^{1,\alpha}$, we prove that if $d \geq 2(1+\alpha)/\alpha$, the lower bound of the convergence rates for single NHT turns out to be worse than the upper bound of the convergence rates for ensemble NHT. In the other case when $k \geq 2$, the NHT may no longer be appropriate in predicting smoother regression functions. Instead, we apply kernel histogram transforms (KHT) equipped with smoother regressors such as support vector machines (SVMs), and it turns out that both single and ensemble KHT enjoy almost optimal convergence rates. Then we validate the above theoretical results by numerical experiments. On the one hand, simulations are conducted to elucidate that ensemble NHT outperform single NHT. On the other hand, the effects of bin sizes on accuracy of both NHT and KHT also accord with theoretical analysis. Last but not least, in the real-data experiments, comparisons between the ensemble KHT, equipped with adaptive histogram transforms, and other state-of-the-art large-scale regression estimators verify the effectiveness and accuracy of our algorithm.