 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHindsight Trust Region Policy Optimization
Paper and Code
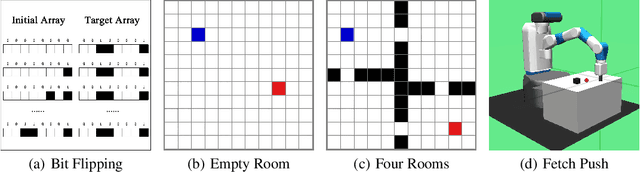
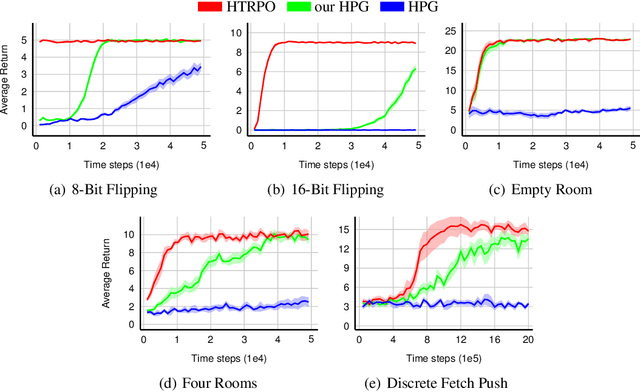
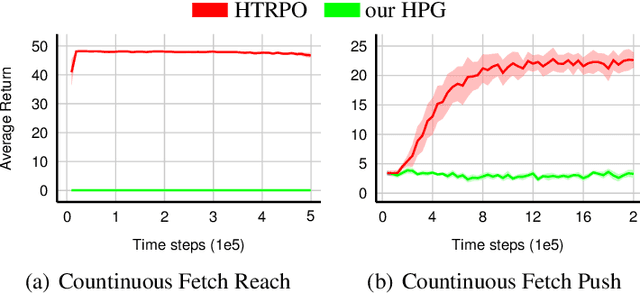
As reinforcement learning continues to drive machine intelligence beyond its conventional boundary, unsubstantial practices in sparse reward environment severely limit further applications in a broader range of advanced fields. Motivated by the demand for an effective deep reinforcement learning algorithm that accommodates sparse reward environment, this paper presents Hindsight Trust Region Policy Optimization (Hindsight TRPO), a method that efficiently utilizes interactions in sparse reward conditions and maintains learning stability by restricting variance during the policy update process. Firstly, the hindsight methodology is expanded to TRPO, an advanced and efficient on-policy policy gradient method. Then, under the condition that the distributions are close, the KL-divergence is appropriately approximated by another $f$-divergence. Such approximation results in the decrease of variance during KL-divergence estimation and alleviates the instability during policy update. Experimental results on both discrete and continuous benchmark tasks demonstrate that Hindsight TRPO converges steadily and significantly faster than previous policy gradient methods. It achieves effective performances and high data-efficiency for training policies in sparse reward environments.