 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHigh-dimensional Asymptotics of Feature Learning: How One Gradient Step Improves the Representation
Paper and Code
May 03, 2022
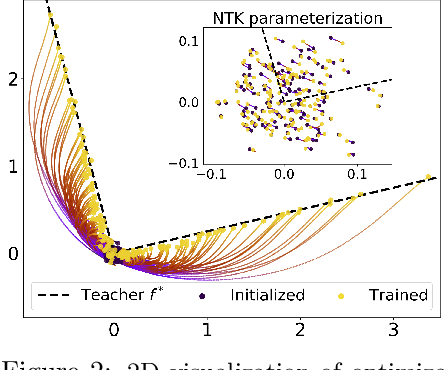
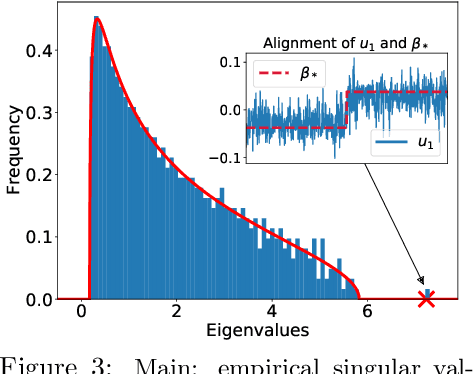
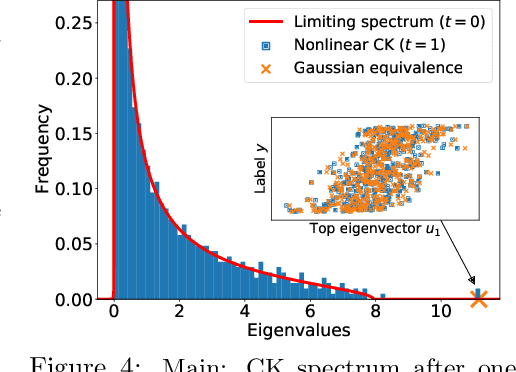
We study the first gradient descent step on the first-layer parameters $\boldsymbol{W}$ in a two-layer neural network: $f(\boldsymbol{x}) = \frac{1}{\sqrt{N}}\boldsymbol{a}^\top\sigma(\boldsymbol{W}^\top\boldsymbol{x})$, where $\boldsymbol{W}\in\mathbb{R}^{d\times N}, \boldsymbol{a}\in\mathbb{R}^{N}$ are randomly initialized, and the training objective is the empirical MSE loss: $\frac{1}{n}\sum_{i=1}^n (f(\boldsymbol{x}_i)-y_i)^2$. In the proportional asymptotic limit where $n,d,N\to\infty$ at the same rate, and an idealized student-teacher setting, we show that the first gradient update contains a rank-1 "spike", which results in an alignment between the first-layer weights and the linear component of the teacher model $f^*$. To characterize the impact of this alignment, we compute the prediction risk of ridge regression on the conjugate kernel after one gradient step on $\boldsymbol{W}$ with learning rate $\eta$, when $f^*$ is a single-index model. We consider two scalings of the first step learning rate $\eta$. For small $\eta$, we establish a Gaussian equivalence property for the trained feature map, and prove that the learned kernel improves upon the initial random features model, but cannot defeat the best linear model on the input. Whereas for sufficiently large $\eta$, we prove that for certain $f^*$, the same ridge estimator on trained features can go beyond this "linear regime" and outperform a wide range of random features and rotationally invariant kernels. Our results demonstrate that even one gradient step can lead to a considerable advantage over random features, and highlight the role of learning rate scaling in the initial phase of training.