 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchical Semantic Aggregation for Contrastive Representation Learning
Paper and Code
Dec 04, 2020

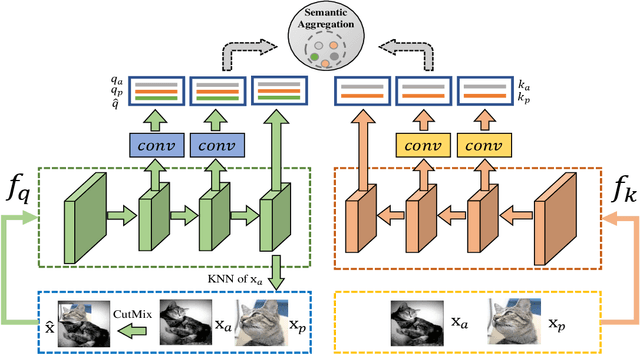
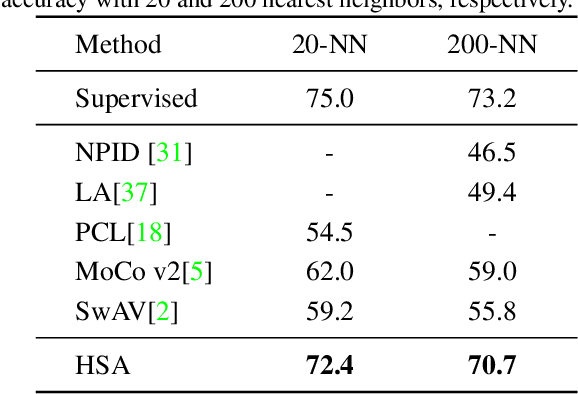
Self-supervised learning based on instance discrimination has shown remarkable progress. In particular, contrastive learning, which regards each image as well as its augmentations as a separate class, and pushes all other images away, has been proved effective for pretraining. However, contrasting two images that are de facto similar in semantic space is hard for optimization and not applicable for general representations. In this paper, we tackle the representation inefficiency of contrastive learning and propose a hierarchical training strategy to explicitly model the invariance to semantic similar images in a bottom-up way. This is achieved by extending the contrastive loss to allow for multiple positives per anchor, and explicitly pulling semantically similar images/patches together at the earlier layers as well as the last embedding space. In this way, we are able to learn feature representation that is more discriminative throughout different layers, which we find is beneficial for fast convergence. The hierarchical semantic aggregation strategy produces more discriminative representation on several unsupervised benchmarks. Notably, on ImageNet with ResNet-50 as backbone, we reach $76.4\%$ top-1 accuracy with linear evaluation, and $75.1\%$ top-1 accuracy with only $10\%$ labels.