 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchical and Unsupervised Graph Representation Learning with Loukas's Coarsening
Paper and Code
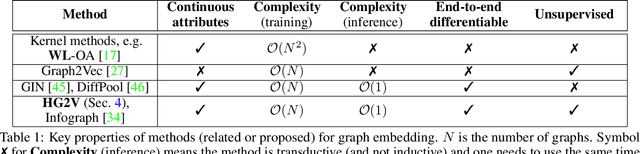
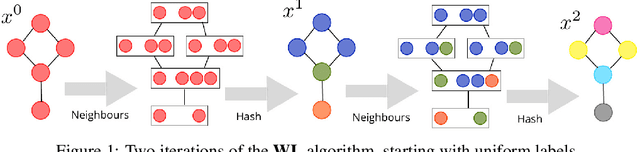
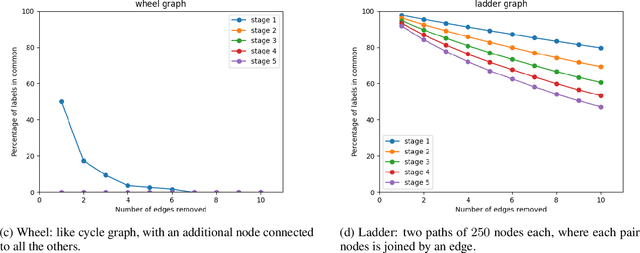
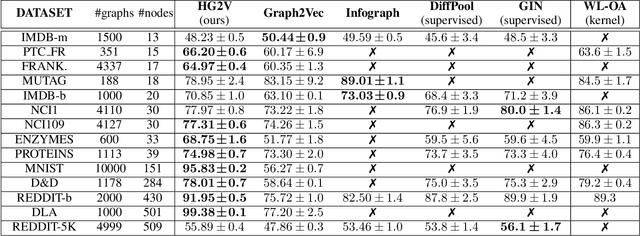
We propose a novel algorithm for unsupervised graph representation learning with attributed graphs. It combines three advantages addressing some current limitations of the literature: i) The model is inductive: it can embed new graphs without re-training in the presence of new data; ii) The method takes into account both micro-structures and macro-structures by looking at the attributed graphs at different scales; iii) The model is end-to-end differentiable: it is a building block that can be plugged into deep learning pipelines and allows for back-propagation. We show that combining a coarsening method having strong theoretical guarantees with mutual information maximization suffices to produce high quality embeddings. We evaluate them on classification tasks with common benchmarks of the literature. We show that our algorithm is competitive with state of the art among unsupervised graph representation learning methods.