 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHEMP: High-order Entropy Minimization for neural network comPression
Paper and Code
Jul 12, 2021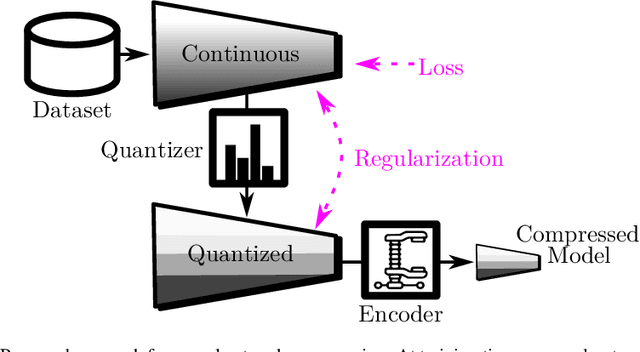

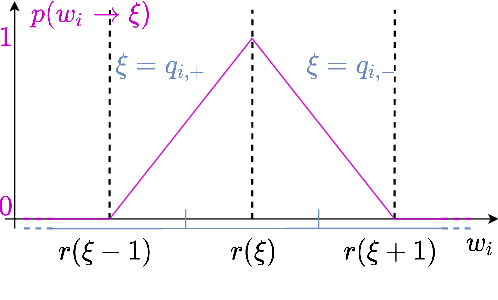
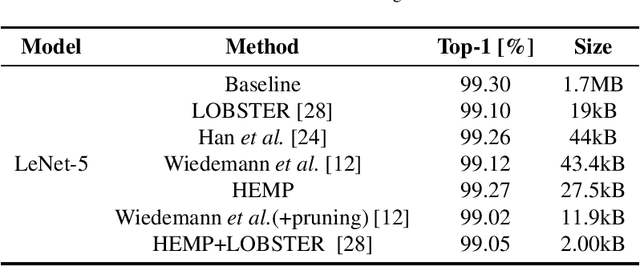
We formulate the entropy of a quantized artificial neural network as a differentiable function that can be plugged as a regularization term into the cost function minimized by gradient descent. Our formulation scales efficiently beyond the first order and is agnostic of the quantization scheme. The network can then be trained to minimize the entropy of the quantized parameters, so that they can be optimally compressed via entropy coding. We experiment with our entropy formulation at quantizing and compressing well-known network architectures over multiple datasets. Our approach compares favorably over similar methods, enjoying the benefits of higher order entropy estimate, showing flexibility towards non-uniform quantization (we use Lloyd-max quantization), scalability towards any entropy order to be minimized and efficiency in terms of compression. We show that HEMP is able to work in synergy with other approaches aiming at pruning or quantizing the model itself, delivering significant benefits in terms of storage size compressibility without harming the model's performance.