 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHarvard Glaucoma Detection and Progression: A Multimodal Multitask Dataset and Generalization-Reinforced Semi-Supervised Learning
Paper and Code
Aug 25, 2023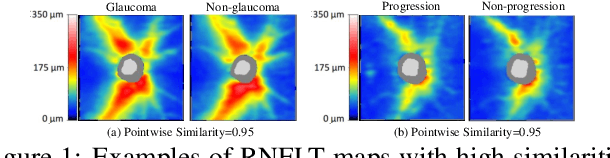
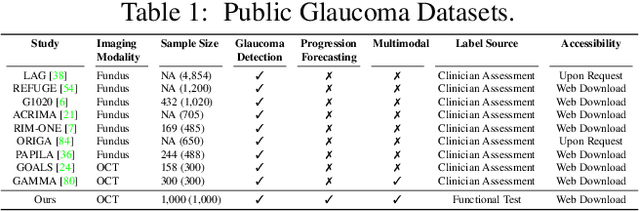
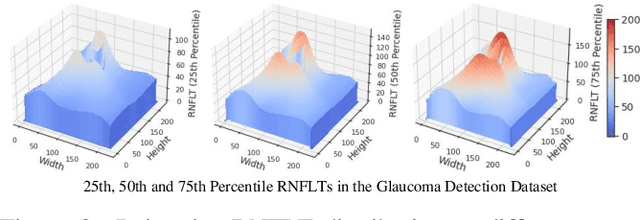
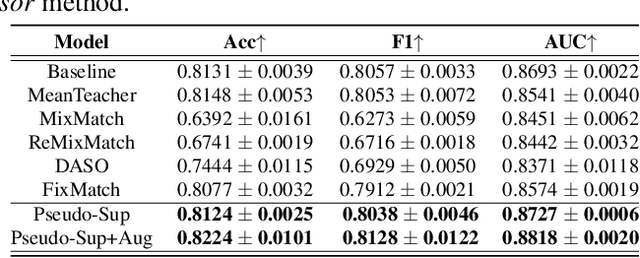
Glaucoma is the number one cause of irreversible blindness globally. A major challenge for accurate glaucoma detection and progression forecasting is the bottleneck of limited labeled patients with the state-of-the-art (SOTA) 3D retinal imaging data of optical coherence tomography (OCT). To address the data scarcity issue, this paper proposes two solutions. First, we develop a novel generalization-reinforced semi-supervised learning (SSL) model called pseudo supervisor to optimally utilize unlabeled data. Compared with SOTA models, the proposed pseudo supervisor optimizes the policy of predicting pseudo labels with unlabeled samples to improve empirical generalization. Our pseudo supervisor model is evaluated with two clinical tasks consisting of glaucoma detection and progression forecasting. The progression forecasting task is evaluated both unimodally and multimodally. Our pseudo supervisor model demonstrates superior performance than SOTA SSL comparison models. Moreover, our model also achieves the best results on the publicly available LAG fundus dataset. Second, we introduce the Harvard Glaucoma Detection and Progression (Harvard-GDP) Dataset, a multimodal multitask dataset that includes data from 1,000 patients with OCT imaging data, as well as labels for glaucoma detection and progression. This is the largest glaucoma detection dataset with 3D OCT imaging data and the first glaucoma progression forecasting dataset that is publicly available. Detailed sex and racial analysis are provided, which can be used by interested researchers for fairness learning studies. Our released dataset is benchmarked with several SOTA supervised CNN and transformer deep learning models. The dataset and code are made publicly available via \url{https://ophai.hms.harvard.edu/datasets/harvard-gdp1000}.