 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHANT: Hardware-Aware Network Transformation
Paper and Code

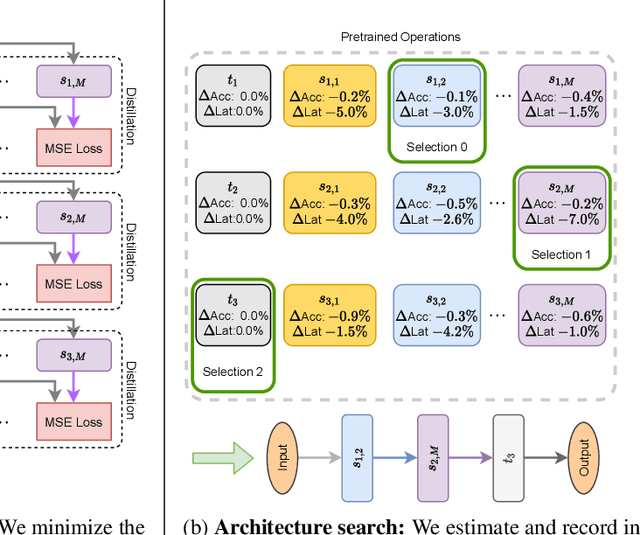
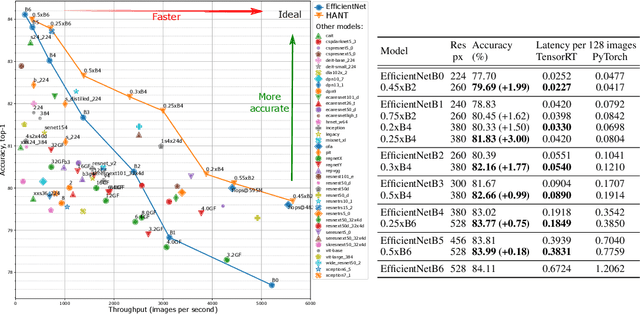
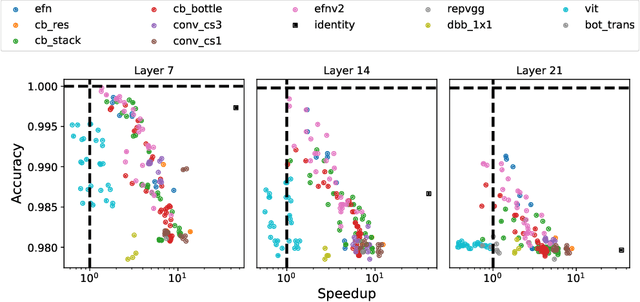
Given a trained network, how can we accelerate it to meet efficiency needs for deployment on particular hardware? The commonly used hardware-aware network compression techniques address this question with pruning, kernel fusion, quantization and lowering precision. However, these approaches do not change the underlying network operations. In this paper, we propose hardware-aware network transformation (HANT), which accelerates a network by replacing inefficient operations with more efficient alternatives using a neural architecture search like approach. HANT tackles the problem in two phase: In the first phase, a large number of alternative operations per every layer of the teacher model is trained using layer-wise feature map distillation. In the second phase, the combinatorial selection of efficient operations is relaxed to an integer optimization problem that can be solved in a few seconds. We extend HANT with kernel fusion and quantization to improve throughput even further. Our experimental results on accelerating the EfficientNet family show that HANT can accelerate them by up to 3.6x with <0.4% drop in the top-1 accuracy on the ImageNet dataset. When comparing the same latency level, HANT can accelerate EfficientNet-B4 to the same latency as EfficientNet-B1 while having 3% higher accuracy. We examine a large pool of operations, up to 197 per layer, and we provide insights into the selected operations and final architectures.