 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHandling Collocations in Hierarchical Latent Tree Analysis for Topic Modeling
Paper and Code
Jul 10, 2020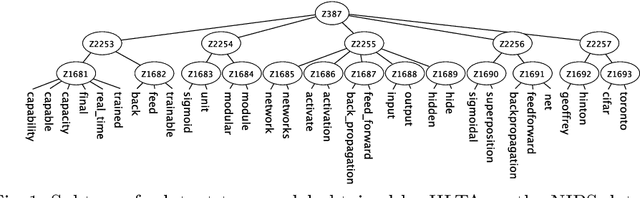

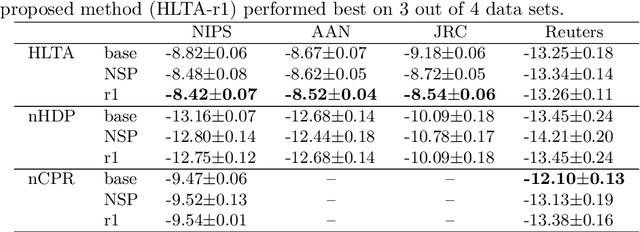
Topic modeling has been one of the most active research areas in machine learning in recent years. Hierarchical latent tree analysis (HLTA) has been recently proposed for hierarchical topic modeling and has shown superior performance over state-of-the-art methods. However, the models used in HLTA have a tree structure and cannot represent the different meanings of multiword expressions sharing the same word appropriately. Therefore, we propose a method for extracting and selecting collocations as a preprocessing step for HLTA. The selected collocations are replaced with single tokens in the bag-of-words model before running HLTA. Our empirical evaluation shows that the proposed method led to better performance of HLTA on three of the four data sets tested.