 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGS-PT: Exploiting 3D Gaussian Splatting for Comprehensive Point Cloud Understanding via Self-supervised Learning
Paper and Code
Sep 08, 2024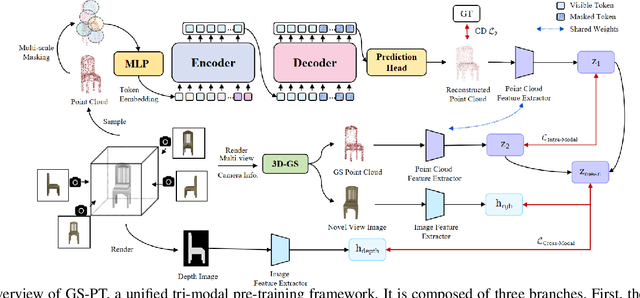
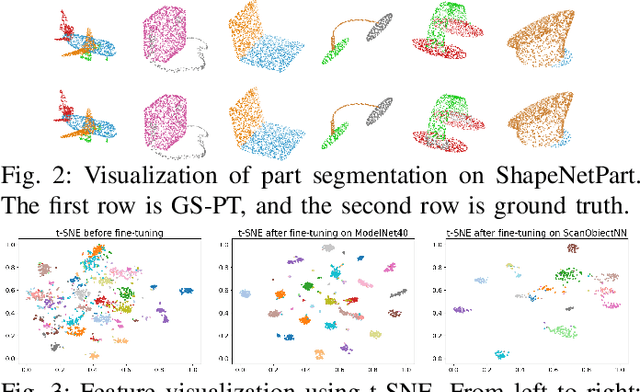
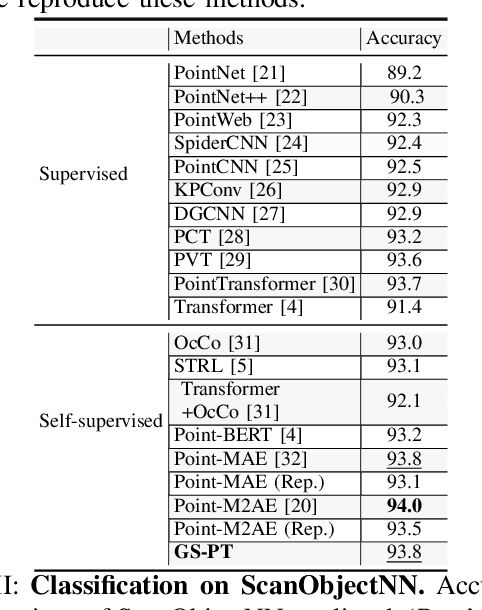
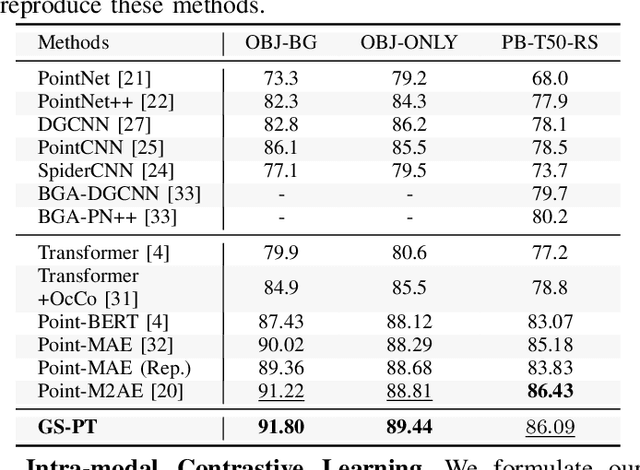
Self-supervised learning of point cloud aims to leverage unlabeled 3D data to learn meaningful representations without reliance on manual annotations. However, current approaches face challenges such as limited data diversity and inadequate augmentation for effective feature learning. To address these challenges, we propose GS-PT, which integrates 3D Gaussian Splatting (3DGS) into point cloud self-supervised learning for the first time. Our pipeline utilizes transformers as the backbone for self-supervised pre-training and introduces novel contrastive learning tasks through 3DGS. Specifically, the transformers aim to reconstruct the masked point cloud. 3DGS utilizes multi-view rendered images as input to generate enhanced point cloud distributions and novel view images, facilitating data augmentation and cross-modal contrastive learning. Additionally, we incorporate features from depth maps. By optimizing these tasks collectively, our method enriches the tri-modal self-supervised learning process, enabling the model to leverage the correlation across 3D point clouds and 2D images from various modalities. We freeze the encoder after pre-training and test the model's performance on multiple downstream tasks. Experimental results indicate that GS-PT outperforms the off-the-shelf self-supervised learning methods on various downstream tasks including 3D object classification, real-world classifications, and few-shot learning and segmentation.