Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraph Kernels: State-of-the-Art and Future Challenges
Paper and Code
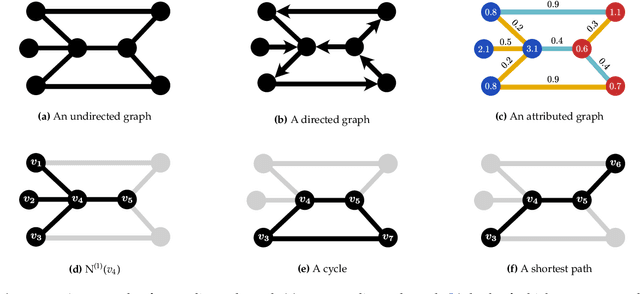
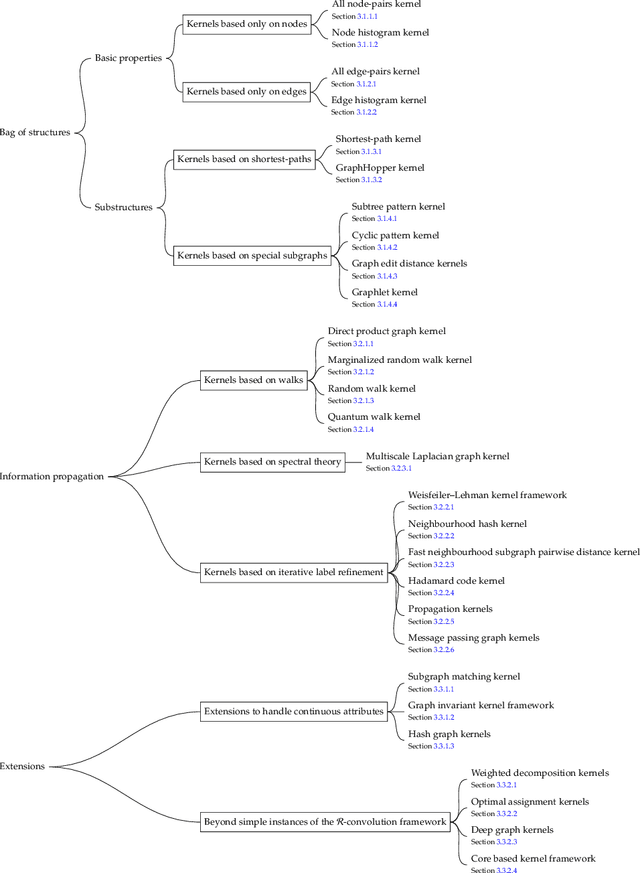
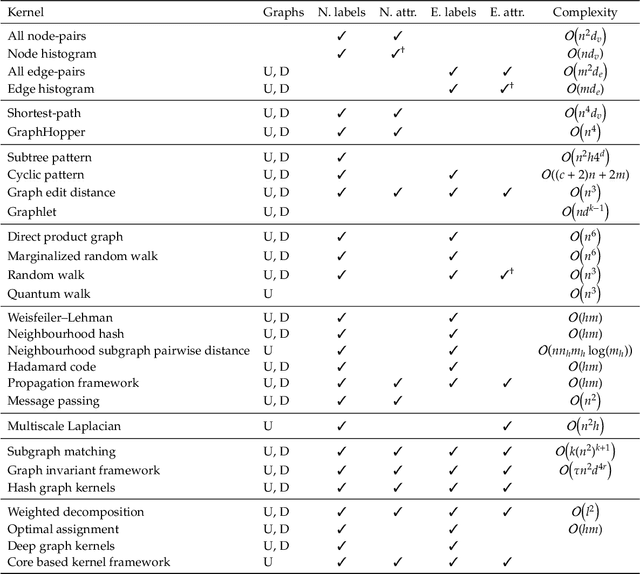
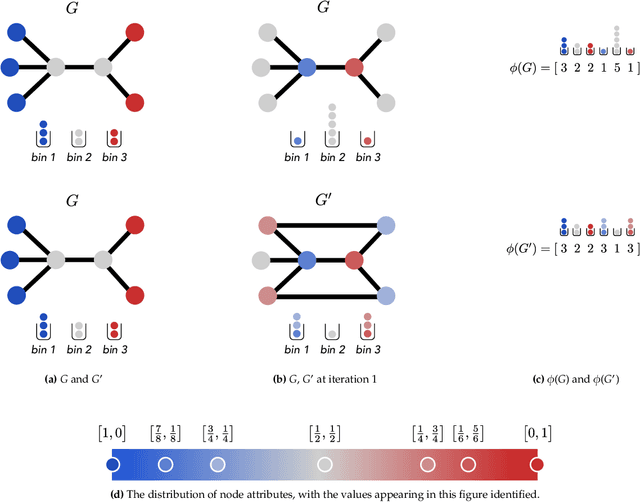
Graph-structured data are an integral part of many application domains, including chemoinformatics, computational biology, neuroimaging, and social network analysis. Over the last two decades, numerous graph kernels, i.e. kernel functions between graphs, have been proposed to solve the problem of assessing the similarity between graphs, thereby making it possible to perform predictions in both classification and regression settings. This manuscript provides a review of existing graph kernels, their applications, software plus data resources, and an empirical comparison of state-of-the-art graph kernels.
* Accepted by Foundations and Trends in Machine Learning, 2020
View paper on