 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGradient-based Bi-level Optimization for Deep Learning: A Survey
Paper and Code
Aug 04, 2022
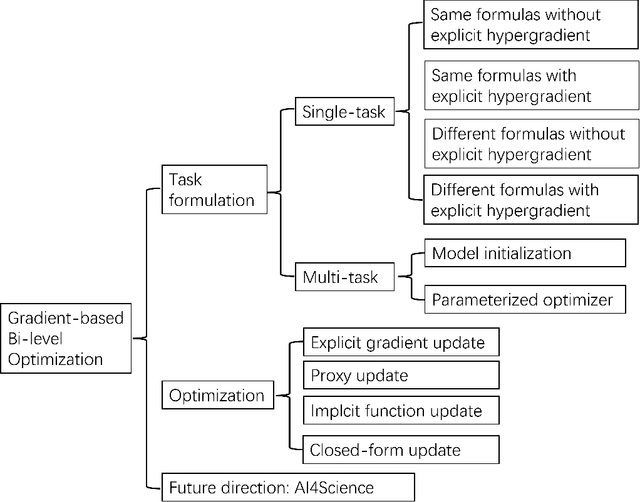
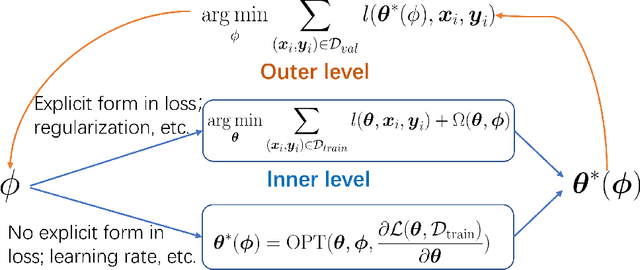
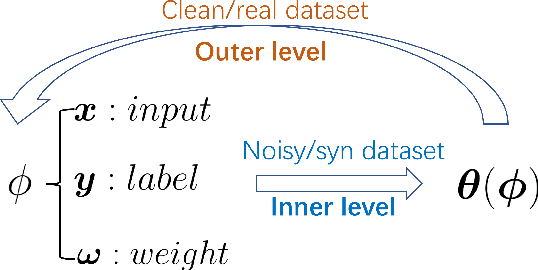
Bi-level optimization, especially the gradient-based category, has been widely used in the deep learning community including hyperparameter optimization and meta knowledge extraction. Bi-level optimization embeds one problem within another and the gradient-based category solves the outer level task by computing the hypergradient, which is much more efficient than classical methods such as the evolutionary algorithm. In this survey, we first give a formal definition of the gradient-based bi-level optimization. Secondly, we illustrate how to formulate a research problem as a bi-level optimization problem, which is of great practical use for beginners. More specifically, there are two formulations: the single-task formulation to optimize hyperparameters such as regularization parameters and the distilled data, and the multi-task formulation to extract meta knowledge such as the model initialization. With a bi-level formulation, we then discuss four bi-level optimization solvers to update the outer variable including explicit gradient update, proxy update, implicit function update, and closed-form update. Last but not least, we conclude the survey by pointing out the great potential of gradient-based bi-level optimization on science problems (AI4Science).