 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGlobally Convergent Policy Search over Dynamic Filters for Output Estimation
Paper and Code
Feb 25, 2022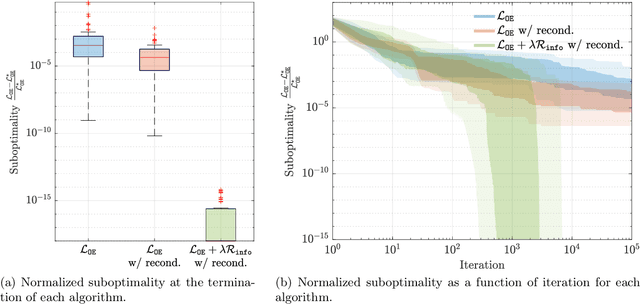
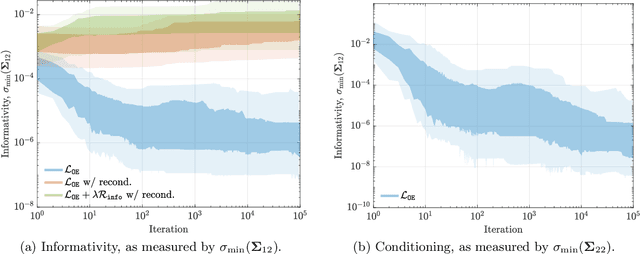
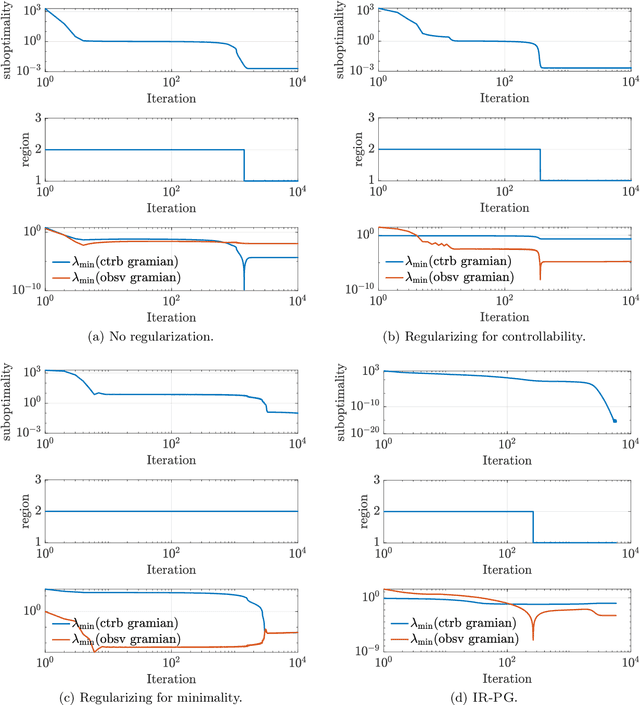
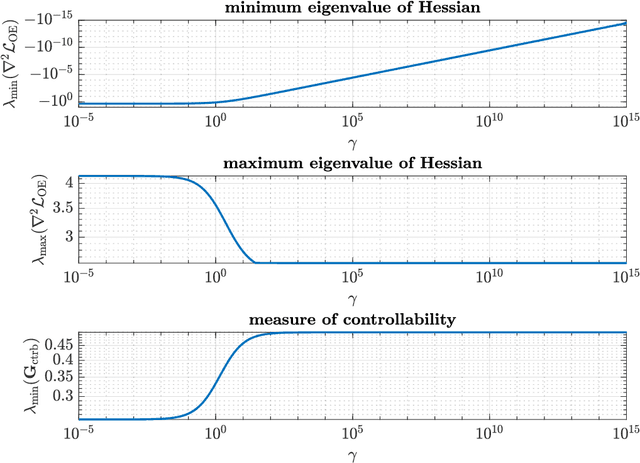
We introduce the first direct policy search algorithm which provably converges to the globally optimal $\textit{dynamic}$ filter for the classical problem of predicting the outputs of a linear dynamical system, given noisy, partial observations. Despite the ubiquity of partial observability in practice, theoretical guarantees for direct policy search algorithms, one of the backbones of modern reinforcement learning, have proven difficult to achieve. This is primarily due to the degeneracies which arise when optimizing over filters that maintain internal state. In this paper, we provide a new perspective on this challenging problem based on the notion of $\textit{informativity}$, which intuitively requires that all components of a filter's internal state are representative of the true state of the underlying dynamical system. We show that informativity overcomes the aforementioned degeneracy. Specifically, we propose a $\textit{regularizer}$ which explicitly enforces informativity, and establish that gradient descent on this regularized objective - combined with a ``reconditioning step'' - converges to the globally optimal cost a $\mathcal{O}(1/T)$ rate. Our analysis relies on several new results which may be of independent interest, including a new framework for analyzing non-convex gradient descent via convex reformulation, and novel bounds on the solution to linear Lyapunov equations in terms of (our quantitative measure of) informativity.