 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGibbs Sampling from Human Feedback: A Provable KL- constrained Framework for RLHF
Paper and Code
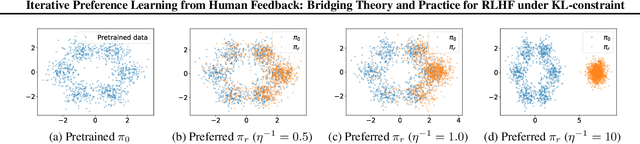

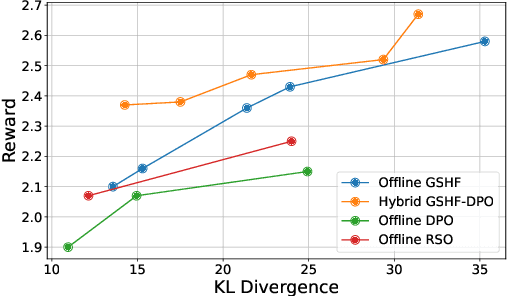
This paper studies the theoretical framework of the alignment process of generative models with Reinforcement Learning from Human Feedback (RLHF). We consider a standard mathematical formulation, the reverse-KL regularized contextual bandit for RLHF. Despite its widespread practical application, a rigorous theoretical analysis of this formulation remains open. We investigate its theoretical properties both in offline and online settings and propose efficient algorithms with finite-sample theoretical guarantees. Our work bridges the gap between theory and practice by linking our theoretical insights with existing practical alignment algorithms such as Direct Preference Optimization (DPO) and Rejection Sampling Optimization (RSO). Furthermore, these findings and connections also offer both theoretical and practical communities new tools and insights for future algorithmic design of alignment algorithms.