 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeometry-Entangled Visual Semantic Transformer for Image Captioning
Paper and Code
Sep 29, 2021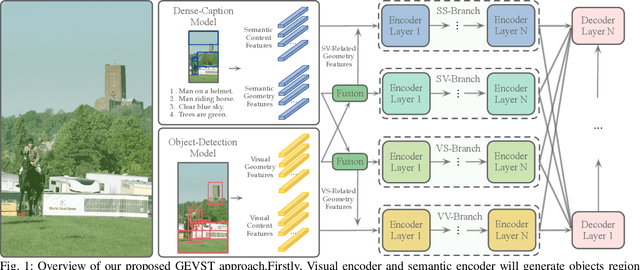
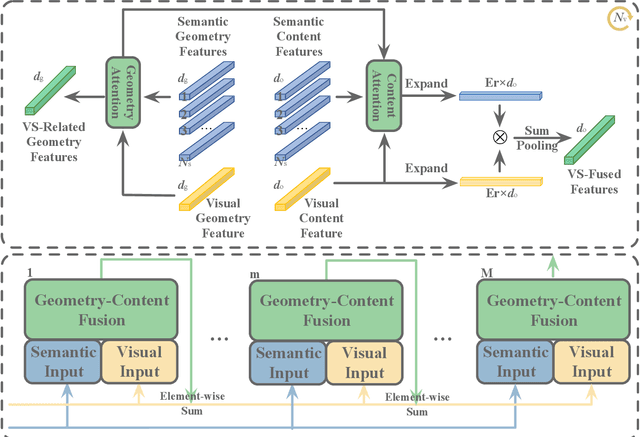
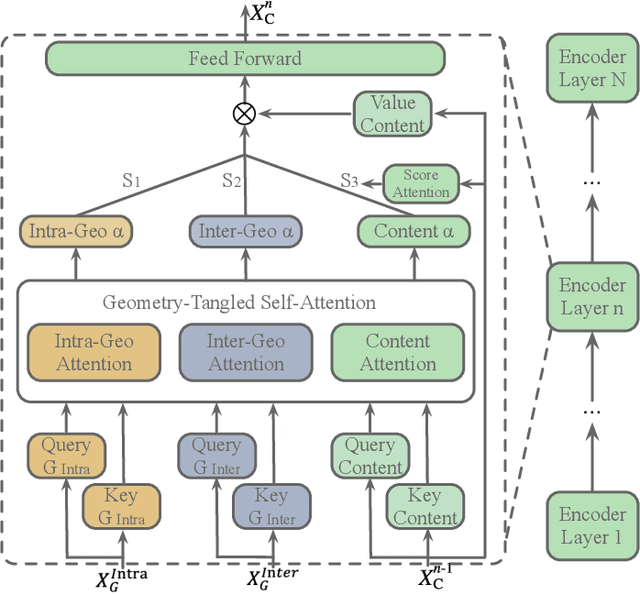
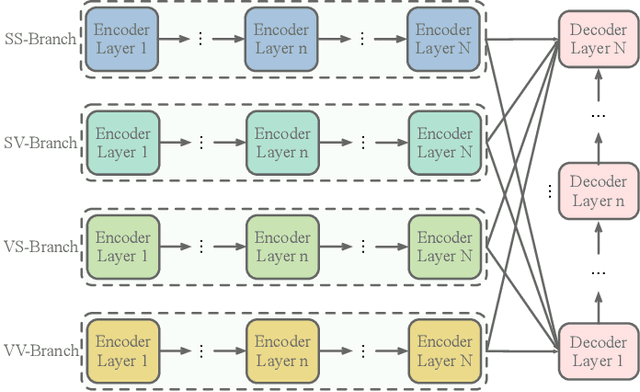
Recent advancements of image captioning have featured Visual-Semantic Fusion or Geometry-Aid attention refinement. However, those fusion-based models, they are still criticized for the lack of geometry information for inter and intra attention refinement. On the other side, models based on Geometry-Aid attention still suffer from the modality gap between visual and semantic information. In this paper, we introduce a novel Geometry-Entangled Visual Semantic Transformer (GEVST) network to realize the complementary advantages of Visual-Semantic Fusion and Geometry-Aid attention refinement. Concretely, a Dense-Cap model proposes some dense captions with corresponding geometry information at first. Then, to empower GEVST with the ability to bridge the modality gap among visual and semantic information, we build four parallel transformer encoders VV(Pure Visual), VS(Semantic fused to Visual), SV(Visual fused to Semantic), SS(Pure Semantic) for final caption generation. Both visual and semantic geometry features are used in the Fusion module and also the Self-Attention module for better attention measurement. To validate our model, we conduct extensive experiments on the MS-COCO dataset, the experimental results show that our GEVST model can obtain promising performance gains.