 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerative Model-Based Loss to the Rescue: A Method to Overcome Annotation Errors for Depth-Based Hand Pose Estimation
Paper and Code
Jul 06, 2020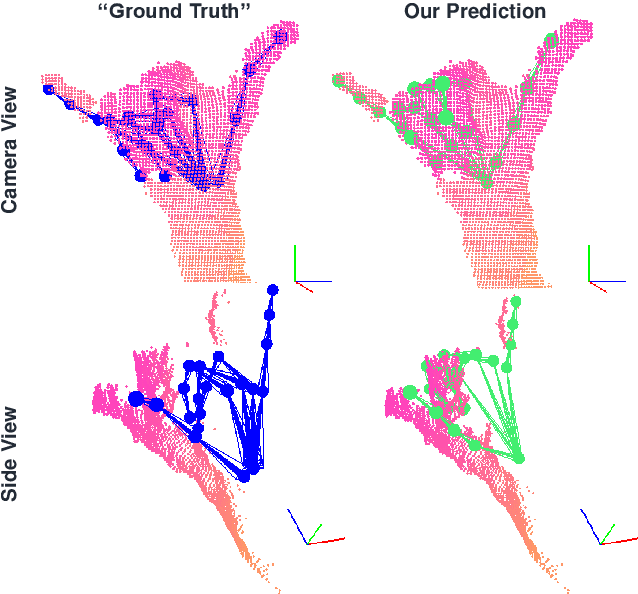
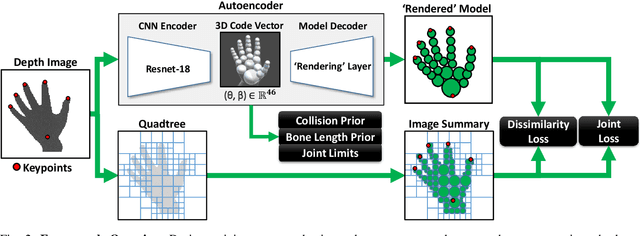
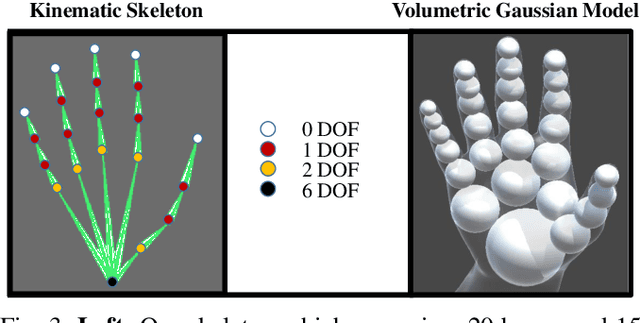
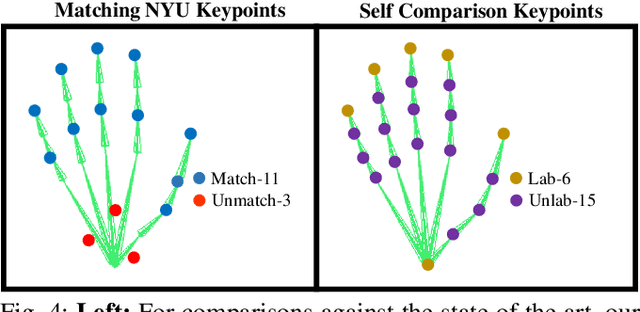
We propose to use a model-based generative loss for training hand pose estimators on depth images based on a volumetric hand model. This additional loss allows training of a hand pose estimator that accurately infers the entire set of 21 hand keypoints while only using supervision for 6 easy-to-annotate keypoints (fingertips and wrist). We show that our partially-supervised method achieves results that are comparable to those of fully-supervised methods which enforce articulation consistency. Moreover, for the first time we demonstrate that such an approach can be used to train on datasets that have erroneous annotations, i.e. "ground truth" with notable measurement errors, while obtaining predictions that explain the depth images better than the given "ground truth".