 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerative Cross-Modal Retrieval: Memorizing Images in Multimodal Language Models for Retrieval and Beyond
Paper and Code
Feb 16, 2024
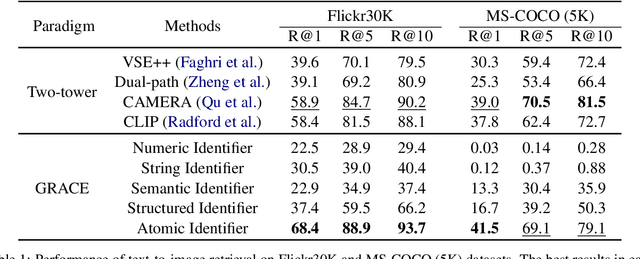


The recent advancements in generative language models have demonstrated their ability to memorize knowledge from documents and recall knowledge to respond to user queries effectively. Building upon this capability, we propose to enable multimodal large language models (MLLMs) to memorize and recall images within their parameters. Given a user query for visual content, the MLLM is anticipated to "recall" the relevant image from its parameters as the response. Achieving this target presents notable challenges, including inbuilt visual memory and visual recall schemes within MLLMs. To address these challenges, we introduce a generative cross-modal retrieval framework, which assigns unique identifier strings to represent images and involves two training steps: learning to memorize and learning to retrieve. The first step focuses on training the MLLM to memorize the association between images and their respective identifiers. The latter step teaches the MLLM to generate the corresponding identifier of the target image, given the textual query input. By memorizing images in MLLMs, we introduce a new paradigm to cross-modal retrieval, distinct from previous discriminative approaches. The experiments demonstrate that the generative paradigm performs effectively and efficiently even with large-scale image candidate sets.