 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneralization Properties of Stochastic Optimizers via Trajectory Analysis
Paper and Code
Aug 02, 2021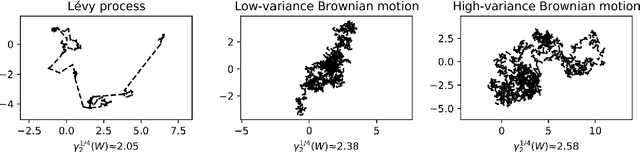
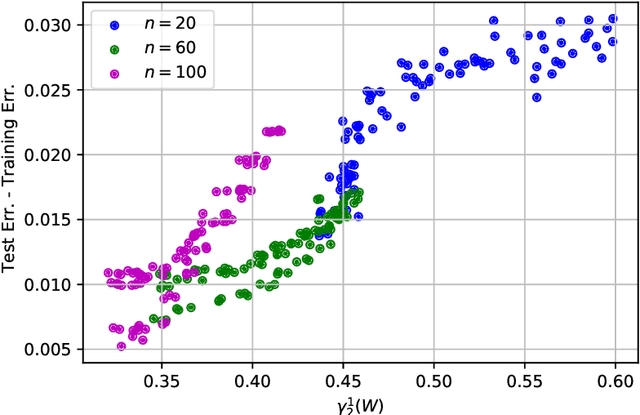
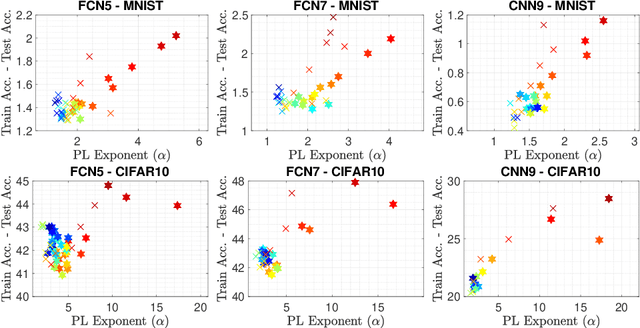
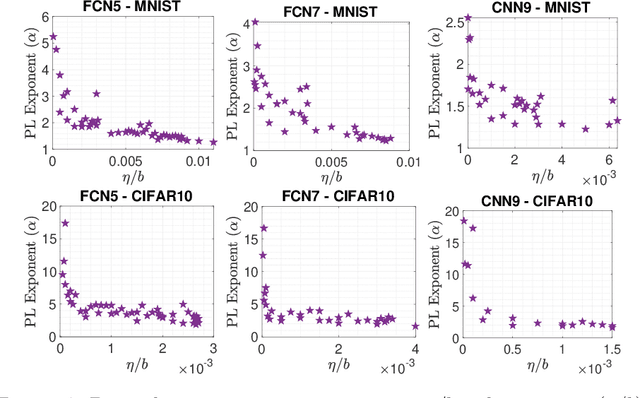
Despite the ubiquitous use of stochastic optimization algorithms in machine learning, the precise impact of these algorithms on generalization performance in realistic non-convex settings is still poorly understood. In this paper, we provide an encompassing theoretical framework for investigating the generalization properties of stochastic optimizers, which is based on their dynamics. We first prove a generalization bound attributable to the optimizer dynamics in terms of the celebrated Fernique-Talagrand functional applied to the trajectory of the optimizer. This data- and algorithm-dependent bound is shown to be the sharpest possible in the absence of further assumptions. We then specialize this result by exploiting the Markovian structure of stochastic optimizers, deriving generalization bounds in terms of the (data-dependent) transition kernels associated with the optimization algorithms. In line with recent work that has revealed connections between generalization and heavy-tailed behavior in stochastic optimization, we link the generalization error to the local tail behavior of the transition kernels. We illustrate that the local power-law exponent of the kernel acts as an effective dimension, which decreases as the transitions become "less Gaussian". We support our theory with empirical results from a variety of neural networks, and we show that both the Fernique-Talagrand functional and the local power-law exponent are predictive of generalization performance.