 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeminiFusion: Efficient Pixel-wise Multimodal Fusion for Vision Transformer
Paper and Code

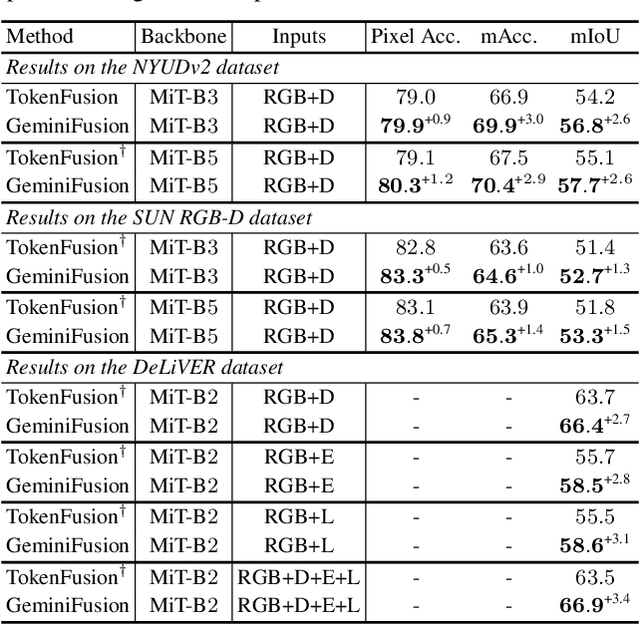


Cross-modal transformers have demonstrated superiority in various vision tasks by effectively integrating different modalities. This paper first critiques prior token exchange methods which replace less informative tokens with inter-modal features, and demonstrate exchange based methods underperform cross-attention mechanisms, while the computational demand of the latter inevitably restricts its use with longer sequences. To surmount the computational challenges, we propose GeminiFusion, a pixel-wise fusion approach that capitalizes on aligned cross-modal representations. GeminiFusion elegantly combines intra-modal and inter-modal attentions, dynamically integrating complementary information across modalities. We employ a layer-adaptive noise to adaptively control their interplay on a per-layer basis, thereby achieving a harmonized fusion process. Notably, GeminiFusion maintains linear complexity with respect to the number of input tokens, ensuring this multimodal framework operates with efficiency comparable to unimodal networks. Comprehensive evaluations across multimodal image-to-image translation, 3D object detection and arbitrary-modal semantic segmentation tasks, including RGB, depth, LiDAR, event data, etc. demonstrate the superior performance of our GeminiFusion against leading-edge techniques. The PyTorch code is available at https://github.com/JiaDingCN/GeminiFusion