 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGADMM: Fast and Communication Efficient Framework for Distributed Machine Learning
Paper and Code
Aug 30, 2019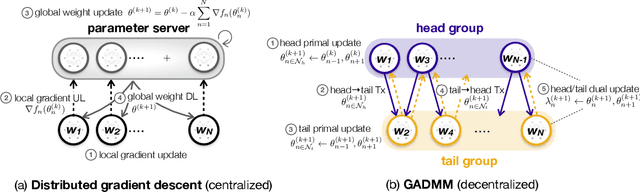
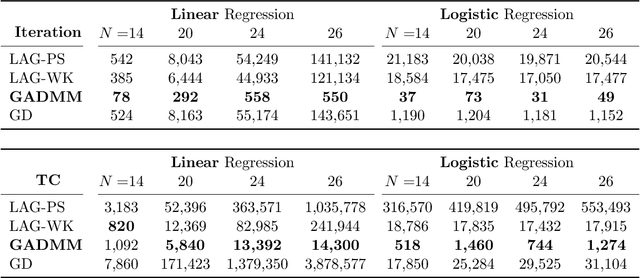
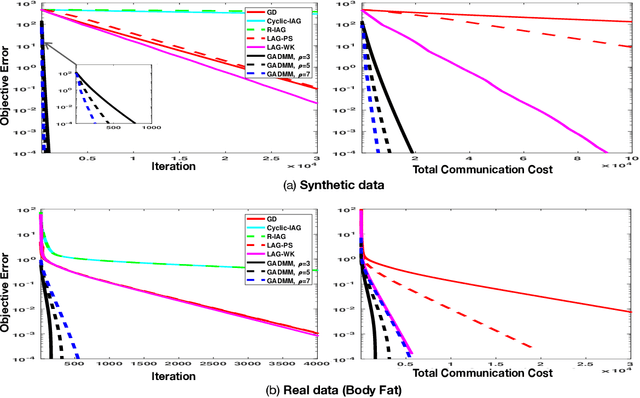
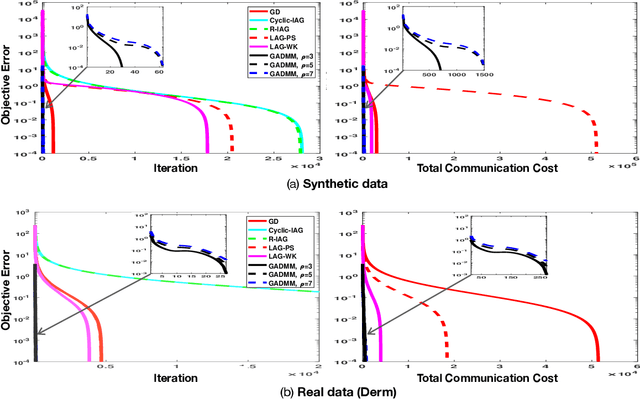
When the data is distributed across multiple servers, efficient data exchange between the servers (or workers) for solving the distributed learning problem is an important problem and is the focus of this paper. We propose a fast, privacy-aware, and communication-efficient decentralized framework to solve the distributed machine learning (DML) problem. The proposed algorithm, GADMM, is based on Alternating Direct Method of Multiplier (ADMM) algorithm. The key novelty in GADMM is that each worker exchanges the locally trained model only with two neighboring workers, thereby training a global model with lower amount of communication in each exchange. We prove that GADMM converges faster than the centralized batch gradient descent for convex loss functions, and numerically show that it is faster and more communication-efficient than the state-of-the-art communication-efficient centralized algorithms such as the Lazily Aggregated Gradient (LAG), in linear and logistic regression tasks on synthetic and real datasets. Furthermore, we propose Dynamic GADMM (D-GADMM), a variant of GADMM, and prove its convergence under time-varying network topology of the workers.