 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFunctional-level Uncertainty Quantification for Calibrated Fine-tuning on LLMs
Paper and Code
Oct 09, 2024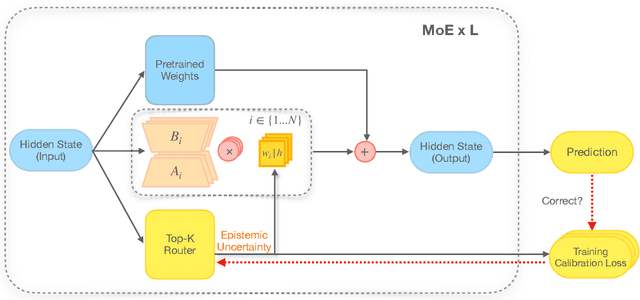
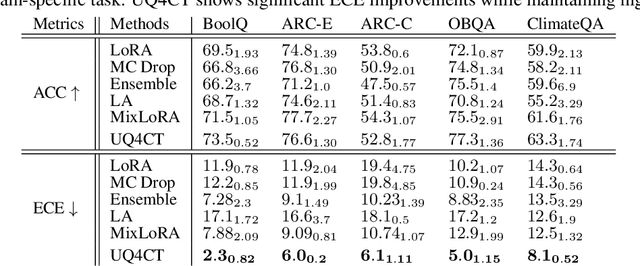
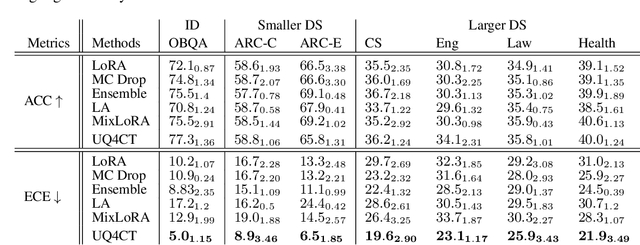
From common-sense reasoning to domain-specific tasks, parameter-efficient fine tuning (PEFT) methods for large language models (LLMs) have showcased significant performance improvements on downstream tasks. However, fine-tuned LLMs often struggle with overconfidence in uncertain predictions, particularly due to sparse training data. This overconfidence reflects poor epistemic uncertainty calibration, which arises from limitations in the model's ability to generalize with limited data. Existing PEFT uncertainty quantification methods for LLMs focus on the post fine-tuning stage and thus have limited capability in calibrating epistemic uncertainty. To address these limitations, we propose Functional-Level Uncertainty Quantification for Calibrated Fine-Tuning (UQ4CT), which captures and calibrates functional-level epistemic uncertainty during the fine-tuning stage via a mixture-of-expert framework. We show that UQ4CT reduces Expected Calibration Error (ECE) by more than $25\%$ while maintaining high accuracy across $5$ benchmarks. Furthermore, UQ4CT maintains superior ECE performance with high accuracy under distribution shift, showcasing improved generalizability.