 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFully-hierarchical fine-grained prosody modeling for interpretable speech synthesis
Paper and Code
Feb 06, 2020
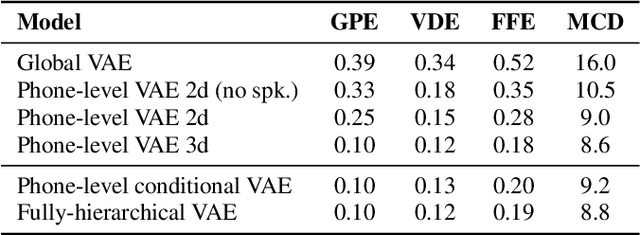


This paper proposes a hierarchical, fine-grained and interpretable latent variable model for prosody based on the Tacotron 2 text-to-speech model. It achieves multi-resolution modeling of prosody by conditioning finer level representations on coarser level ones. Additionally, it imposes hierarchical conditioning across all latent dimensions using a conditional variational auto-encoder (VAE) with an auto-regressive structure. Evaluation of reconstruction performance illustrates that the new structure does not degrade the model while allowing better interpretability. Interpretations of prosody attributes are provided together with the comparison between word-level and phone-level prosody representations. Moreover, both qualitative and quantitative evaluations are used to demonstrate the improvement in the disentanglement of the latent dimensions.