 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFully Distributed Multi-Robot Collision Avoidance via Deep Reinforcement Learning for Safe and Efficient Navigation in Complex Scenarios
Paper and Code

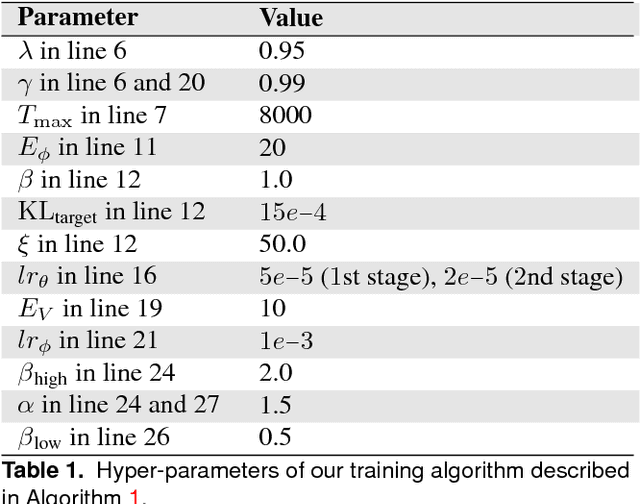
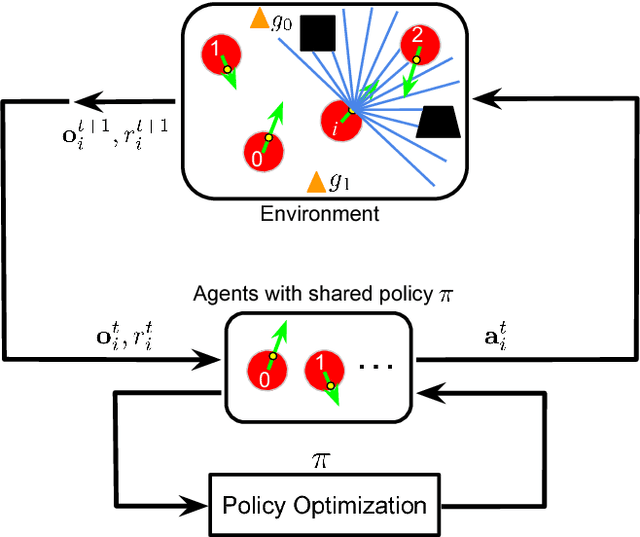
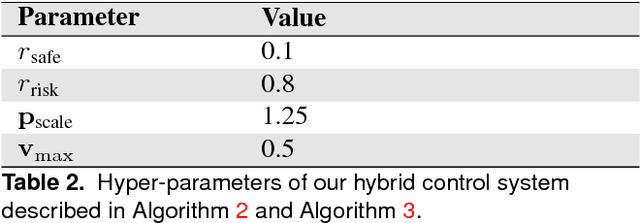
In this paper, we present a decentralized sensor-level collision avoidance policy for multi-robot systems, which shows promising results in practical applications. In particular, our policy directly maps raw sensor measurements to an agent's steering commands in terms of the movement velocity. As a first step toward reducing the performance gap between decentralized and centralized methods, we present a multi-scenario multi-stage training framework to learn an optimal policy. The policy is trained over a large number of robots in rich, complex environments simultaneously using a policy gradient based reinforcement learning algorithm. The learning algorithm is also integrated into a hybrid control framework to further improve the policy's robustness and effectiveness. We validate the learned sensor-level collision avoidance policy in a variety of simulated and real-world scenarios with thorough performance evaluations for large-scale multi-robot systems. The generalization of the learned policy is verified in a set of unseen scenarios including the navigation of a group of heterogeneous robots and a large-scale scenario with 100 robots. Although the policy is trained using simulation data only, we have successfully deployed it on physical robots with shapes and dynamics characteristics that are different from the simulated agents, in order to demonstrate the controller's robustness against the sim-to-real modeling error. Finally, we show that the collision-avoidance policy learned from multi-robot navigation tasks provides an excellent solution to the safe and effective autonomous navigation for a single robot working in a dense real human crowd. Our learned policy enables a robot to make effective progress in a crowd without getting stuck. Videos are available at https://sites.google.com/view/hybridmrca