 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Pointwise to Powerhouse: Initialising Neural Networks with Generative Models
Paper and Code
Oct 25, 2023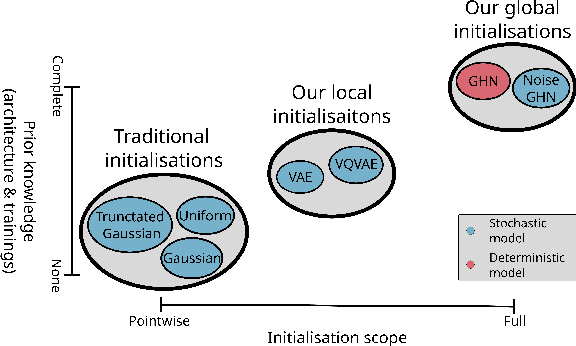
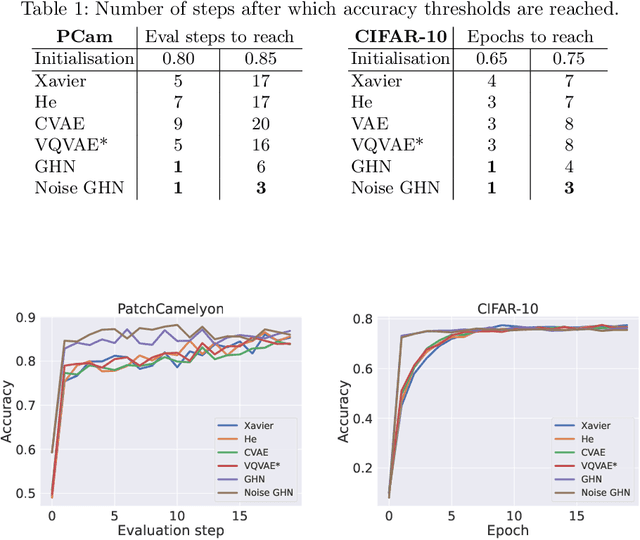
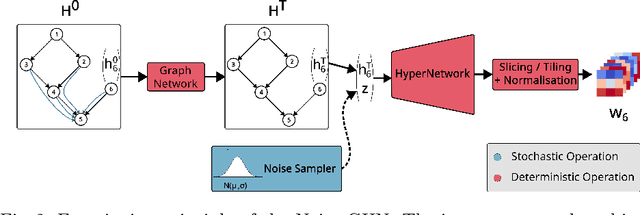
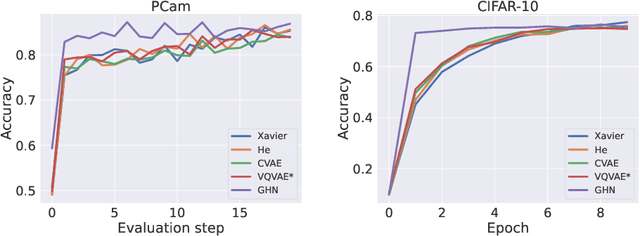
Traditional initialisation methods, e.g. He and Xavier, have been effective in avoiding the problem of vanishing or exploding gradients in neural networks. However, they only use simple pointwise distributions, which model one-dimensional variables. Moreover, they ignore most information about the architecture and disregard past training experiences. These limitations can be overcome by employing generative models for initialisation. In this paper, we introduce two groups of new initialisation methods. First, we locally initialise weight groups by employing variational autoencoders. Secondly, we globally initialise full weight sets by employing graph hypernetworks. We thoroughly evaluate the impact of the employed generative models on state-of-the-art neural networks in terms of accuracy, convergence speed and ensembling. Our results show that global initialisations result in higher accuracy and faster initial convergence speed. However, the implementation through graph hypernetworks leads to diminished ensemble performance on out of distribution data. To counteract, we propose a modification called noise graph hypernetwork, which encourages diversity in the produced ensemble members. Furthermore, our approach might be able to transfer learned knowledge to different image distributions. Our work provides insights into the potential, the trade-offs and possible modifications of these new initialisation methods.