 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Gene Expression to Drug Response: A Collaborative Filtering Approach
Paper and Code
Oct 31, 2018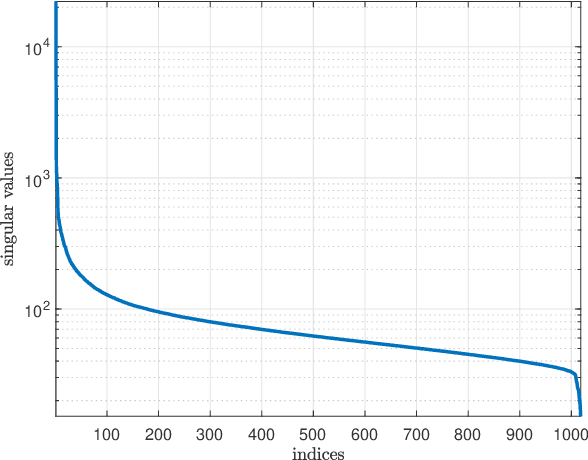
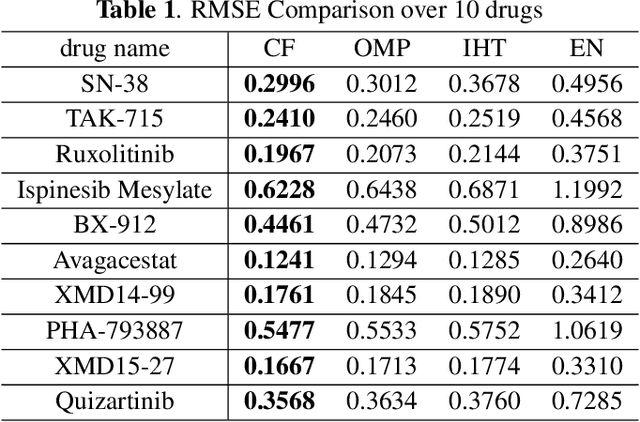
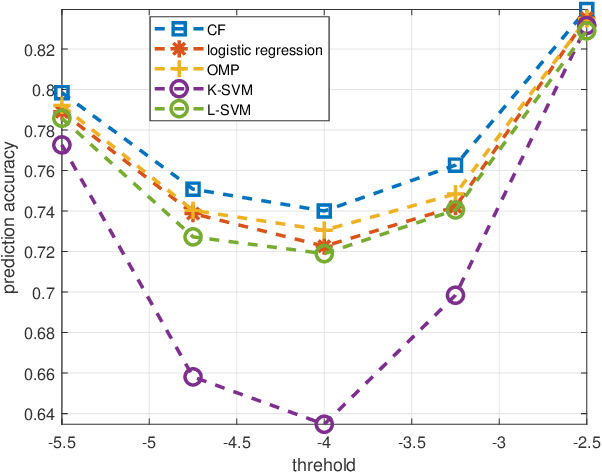
Predicting the response of cancer cells to drugs is an important problem in pharmacogenomics. Recent efforts in generation of large scale datasets profiling gene expression and drug sensitivity in cell lines have provided a unique opportunity to study this problem. However, one major challenge is the small number of samples (cell lines) compared to the number of features (genes) even in these large datasets. We propose a collaborative filtering (CF) like algorithm for modeling gene-drug relationship to identify patients most likely to benefit from a treatment. Due to the correlation of gene expressions in different cell lines, the gene expression matrix is approximately low-rank, which suggests that drug responses could be estimated from a reduced dimension latent space of the gene expression. Towards this end, we propose a joint low-rank matrix factorization and latent linear regression approach. Experiments with data from the Genomics of Drug Sensitivity in Cancer database are included to show that the proposed method can predict drug-gene associations better than the state-of-the-art methods.