 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlowX: Towards Explainable Graph Neural Networks via Message Flows
Paper and Code
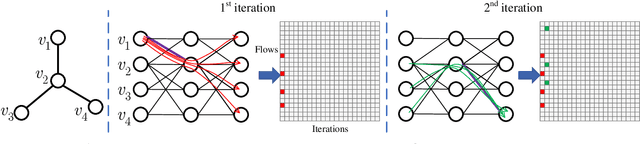
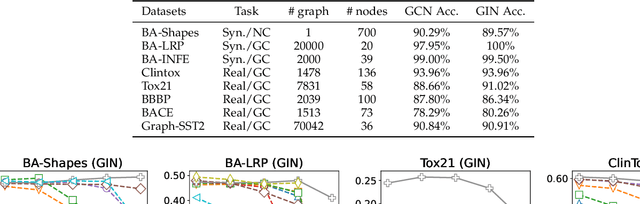
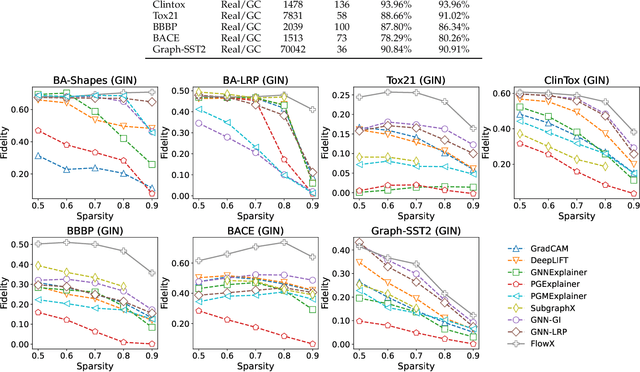
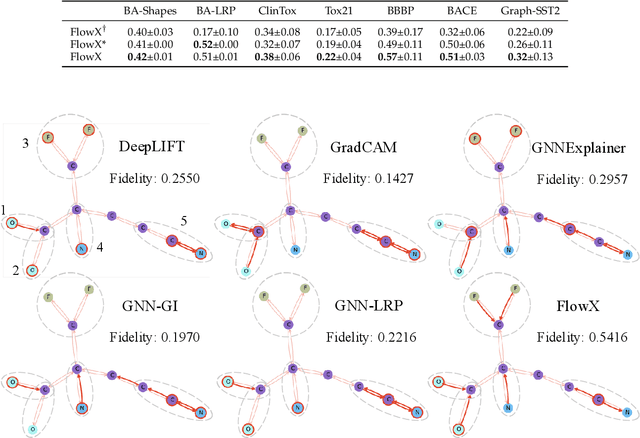
We investigate the explainability of graph neural networks (GNNs) as a step towards elucidating their working mechanisms. While most current methods focus on explaining graph nodes, edges, or features, we argue that, as the inherent functional mechanism of GNNs, message flows are more natural for performing explainability. To this end, we propose a novel method here, known as FlowX, to explain GNNs by identifying important message flows. To quantify the importance of flows, we propose to follow the philosophy of Shapley values from cooperative game theory. To tackle the complexity of computing all coalitions' marginal contributions, we propose an approximation scheme to compute Shapley-like values as initial assessments of further redistribution training. We then propose a learning algorithm to train flow scores and improve explainability. Experimental studies on both synthetic and real-world datasets demonstrate that our proposed FlowX leads to improved explainability of GNNs.