 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlashP: An Analytical Pipeline for Real-time Forecasting of Time-Series Relational Data
Paper and Code
Jan 16, 2021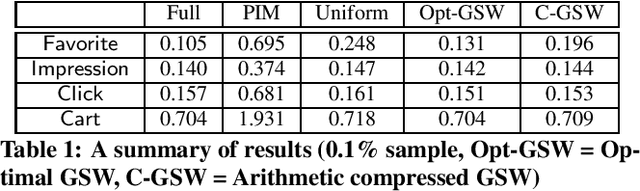
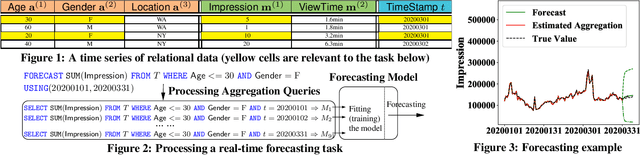

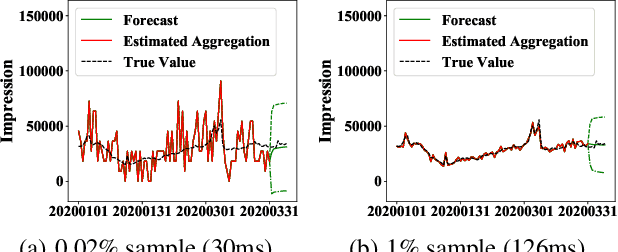
Interactive response time is important in analytical pipelines for users to explore a sufficient number of possibilities and make informed business decisions. We consider a forecasting pipeline with large volumes of high-dimensional time series data. Real-time forecasting can be conducted in two steps. First, we specify the part of data to be focused on and the measure to be predicted by slicing, dicing, and aggregating the data. Second, a forecasting model is trained on the aggregated results to predict the trend of the specified measure. While there are a number of forecasting models available, the first step is the performance bottleneck. A natural idea is to utilize sampling to obtain approximate aggregations in real time as the input to train the forecasting model. Our scalable real-time forecasting system FlashP (Flash Prediction) is built based on this idea, with two major challenges to be resolved in this paper: first, we need to figure out how approximate aggregations affect the fitting of forecasting models, and forecasting results; and second, accordingly, what sampling algorithms we should use to obtain these approximate aggregations and how large the samples are. We introduce a new sampling scheme, called GSW sampling, and analyze error bounds for estimating aggregations using GSW samples. We introduce how to construct compact GSW samples with the existence of multiple measures to be analyzed. We conduct experiments to evaluate our solution and compare it with alternatives on real data.