 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFinding the needle in high-dimensional haystack: A tutorial on canonical correlation analysis
Paper and Code
Dec 06, 2018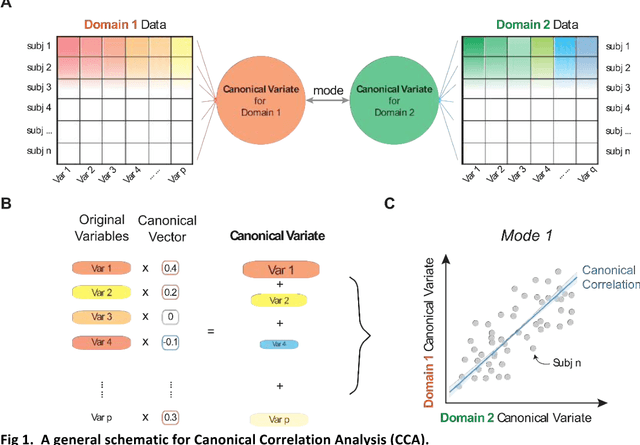
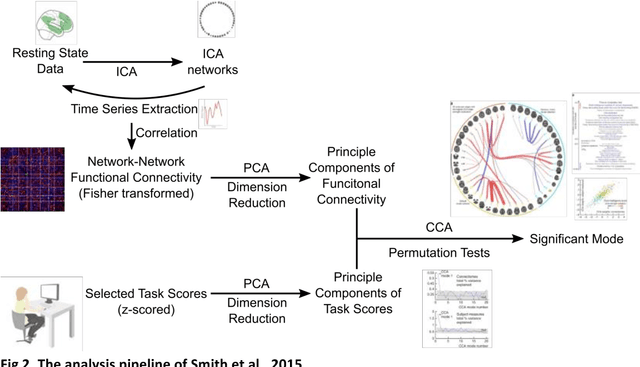
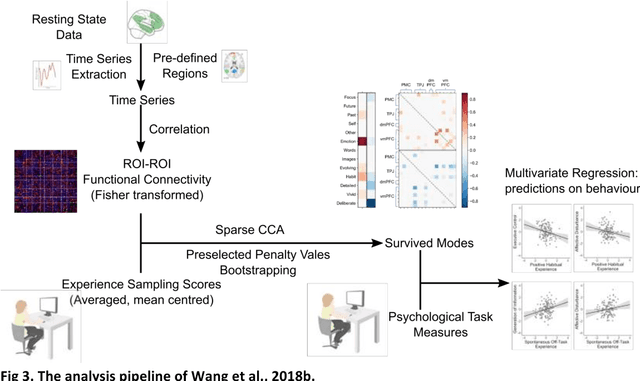
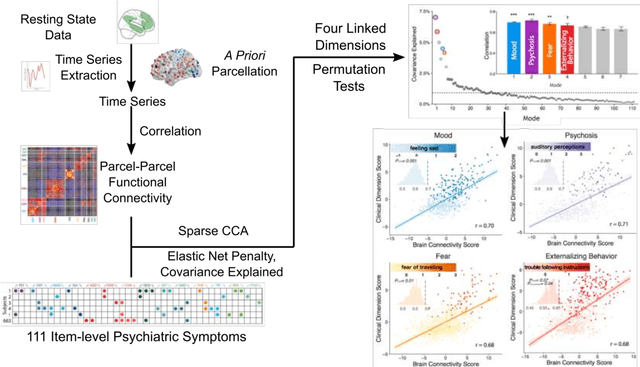
Since the beginning of the 21st century, the size, breadth, and granularity of data in biology and medicine has grown rapidly. In the example of neuroscience, studies with thousands of subjects are becoming more common, which provide extensive phenotyping on the behavioral, neural, and genomic level with hundreds of variables. The complexity of such big data repositories offer new opportunities and pose new challenges to investigate brain, cognition, and disease. Canonical correlation analysis (CCA) is a prototypical family of methods for wrestling with and harvesting insight from such rich datasets. This doubly-multivariate tool can simultaneously consider two variable sets from different modalities to uncover essential hidden associations. Our primer discusses the rationale, promises, and pitfalls of CCA in biomedicine.