 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFinding Eyewitness Tweets During Crises
Paper and Code
Mar 07, 2014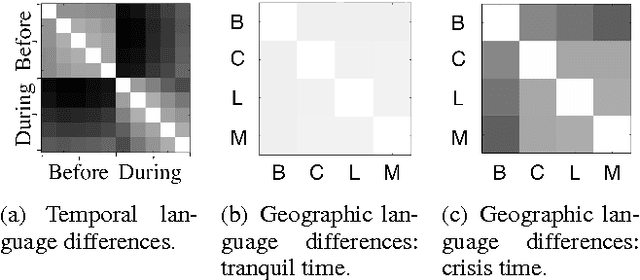
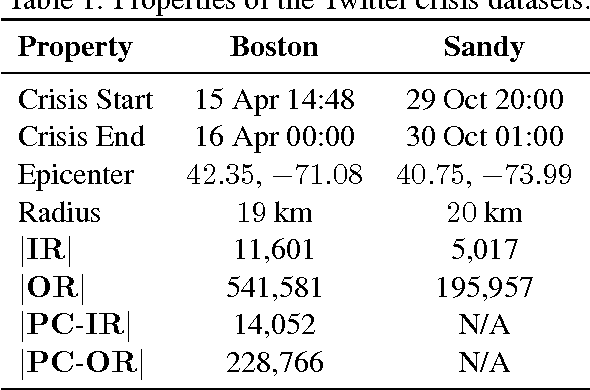
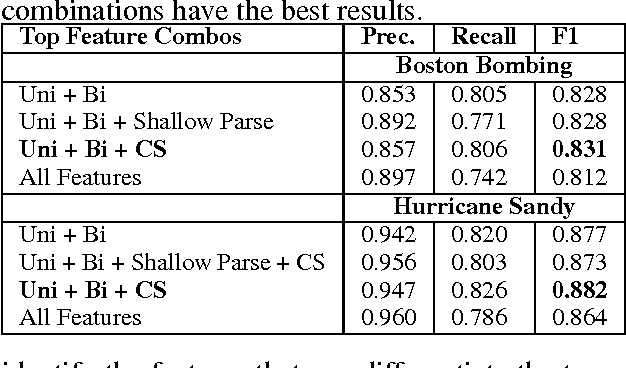

Disaster response agencies have started to incorporate social media as a source of fast-breaking information to understand the needs of people affected by the many crises that occur around the world. These agencies look for tweets from within the region affected by the crisis to get the latest updates of the status of the affected region. However only 1% of all tweets are geotagged with explicit location information. First responders lose valuable information because they cannot assess the origin of many of the tweets they collect. In this work we seek to identify non-geotagged tweets that originate from within the crisis region. Towards this, we address three questions: (1) is there a difference between the language of tweets originating within a crisis region and tweets originating outside the region, (2) what are the linguistic patterns that can be used to differentiate within-region and outside-region tweets, and (3) for non-geotagged tweets, can we automatically identify those originating within the crisis region in real-time?