 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFederated Self-Supervised Contrastive Learning via Ensemble Similarity Distillation
Paper and Code
Sep 29, 2021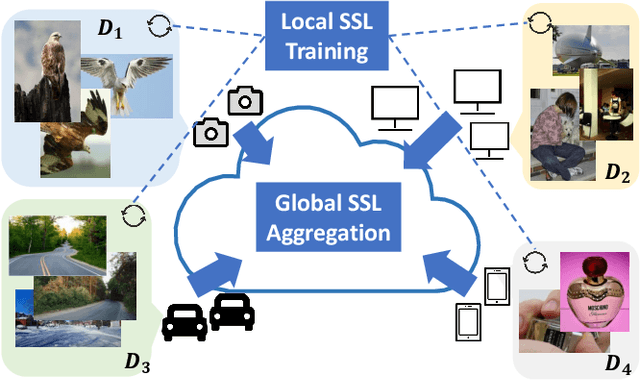

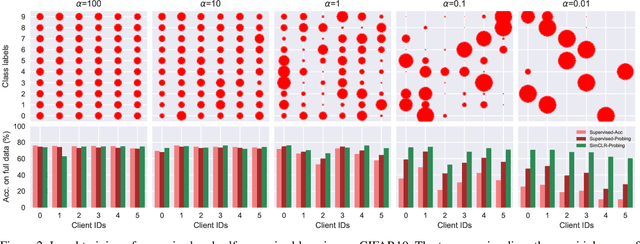
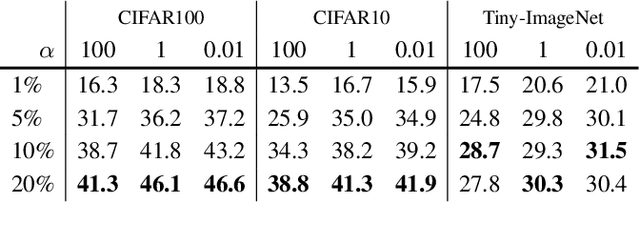
This paper investigates the feasibility of learning good representation space with unlabeled client data in the federated scenario. Existing works trivially inherit the supervised federated learning methods, which does not apply to the model heterogeneity and has the potential risk of privacy exposure. To tackle the problems above, we first identify that self-supervised contrastive local training is more robust against the non-i.i.d.-ness than the traditional supervised learning paradigm. Then we propose a novel federated self-supervised contrastive learning framework FLESD that supports architecture-agnostic local training and communication-efficient global aggregation. At each round of communication, the server first gathers a fraction of the clients' inferred similarity matrices on a public dataset. Then FLESD ensembles the similarity matrices and trains the global model via similarity distillation. We verify the effectiveness of our proposed framework by a series of empirical experiments and show that FLESD has three main advantages over the existing methods: it handles the model heterogeneity, is less prone to privacy leak, and is more communication-efficient. We will release the code of this paper in the future.