 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFAVOR#: Sharp Attention Kernel Approximations via New Classes of Positive Random Features
Paper and Code
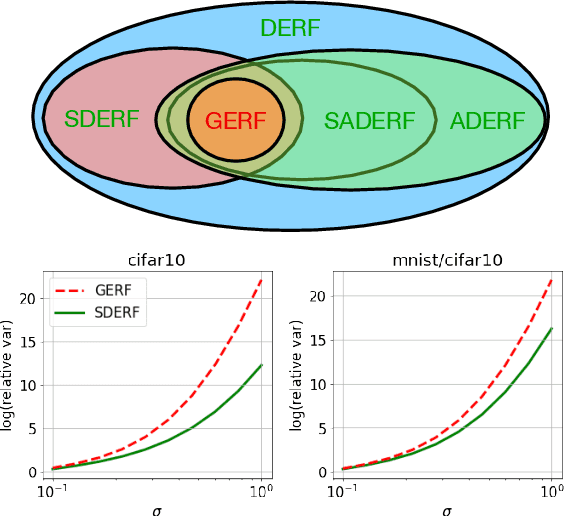
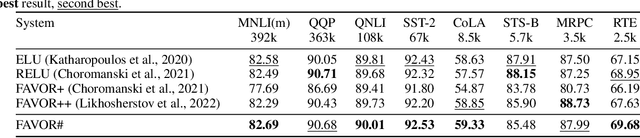
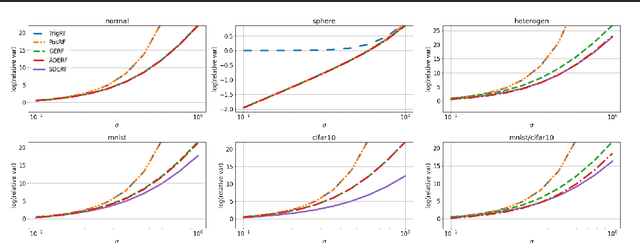
The problem of efficient approximation of a linear operator induced by the Gaussian or softmax kernel is often addressed using random features (RFs) which yield an unbiased approximation of the operator's result. Such operators emerge in important applications ranging from kernel methods to efficient Transformers. We propose parameterized, positive, non-trigonometric RFs which approximate Gaussian and softmax-kernels. In contrast to traditional RF approximations, parameters of these new methods can be optimized to reduce the variance of the approximation, and the optimum can be expressed in closed form. We show that our methods lead to variance reduction in practice ($e^{10}$-times smaller variance and beyond) and outperform previous methods in a kernel regression task. Using our proposed mechanism, we also present FAVOR#, a method for self-attention approximation in Transformers. We show that FAVOR# outperforms other random feature methods in speech modelling and natural language processing.