 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFastWave: Accelerating Autoregressive Convolutional Neural Networks on FPGA
Paper and Code
Feb 09, 2020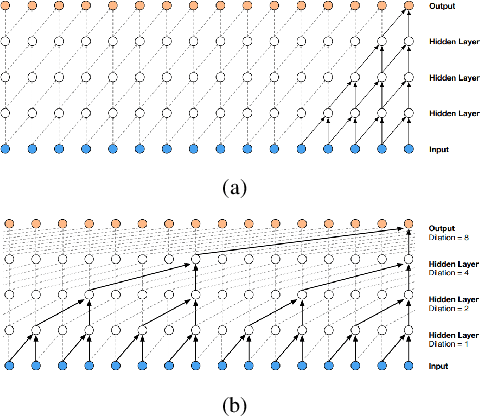
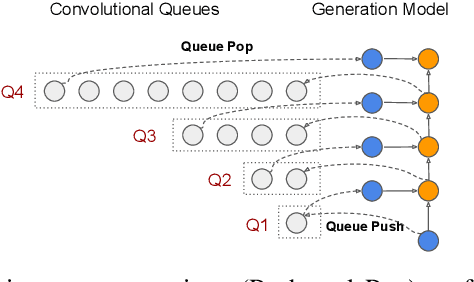
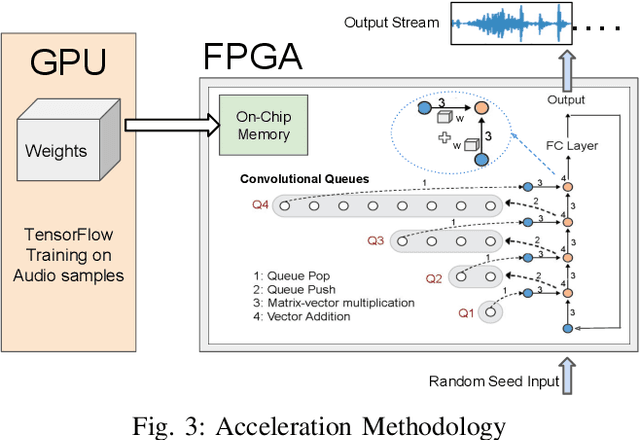
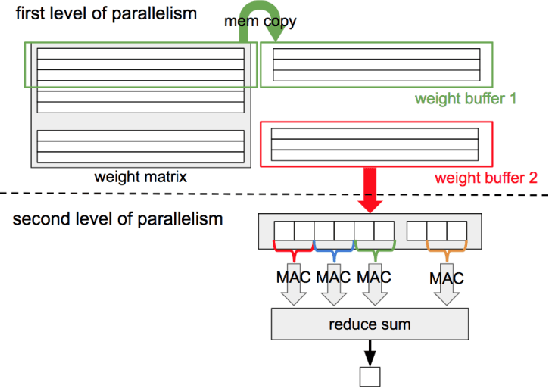
Autoregressive convolutional neural networks (CNNs) have been widely exploited for sequence generation tasks such as audio synthesis, language modeling and neural machine translation. WaveNet is a deep autoregressive CNN composed of several stacked layers of dilated convolution that is used for sequence generation. While WaveNet produces state-of-the art audio generation results, the naive inference implementation is quite slow; it takes a few minutes to generate just one second of audio on a high-end GPU. In this work, we develop the first accelerator platform~\textit{FastWave} for autoregressive convolutional neural networks, and address the associated design challenges. We design the Fast-Wavenet inference model in Vivado HLS and perform a wide range of optimizations including fixed-point implementation, array partitioning and pipelining. Our model uses a fully parameterized parallel architecture for fast matrix-vector multiplication that enables per-layer customized latency fine-tuning for further throughput improvement. Our experiments comparatively assess the trade-off between throughput and resource utilization for various optimizations. Our best WaveNet design on the Xilinx XCVU13P FPGA that uses only on-chip memory, achieves 66 faster generation speed compared to CPU implementation and 11 faster generation speed than GPU implementation.