 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFast Hyperparameter Tuning using Bayesian Optimization with Directional Derivatives
Paper and Code
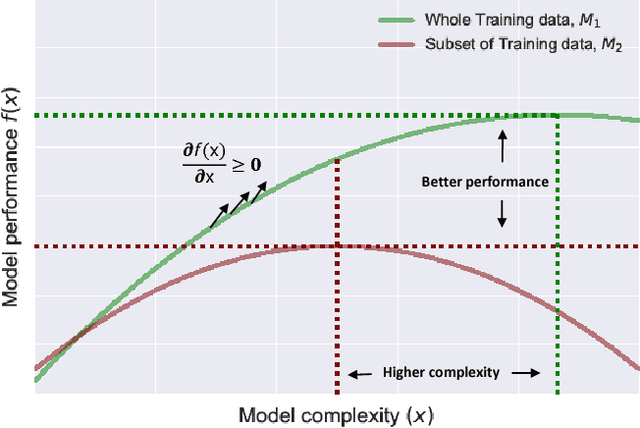



In this paper we develop a Bayesian optimization based hyperparameter tuning framework inspired by statistical learning theory for classifiers. We utilize two key facts from PAC learning theory; the generalization bound will be higher for a small subset of data compared to the whole, and the highest accuracy for a small subset of data can be achieved with a simple model. We initially tune the hyperparameters on a small subset of training data using Bayesian optimization. While tuning the hyperparameters on the whole training data, we leverage the insights from the learning theory to seek more complex models. We realize this by using directional derivative signs strategically placed in the hyperparameter search space to seek a more complex model than the one obtained with small data. We demonstrate the performance of our method on the tasks of tuning the hyperparameters of several machine learning algorithms.