 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFast Fair Regression via Efficient Approximations of Mutual Information
Paper and Code
Feb 14, 2020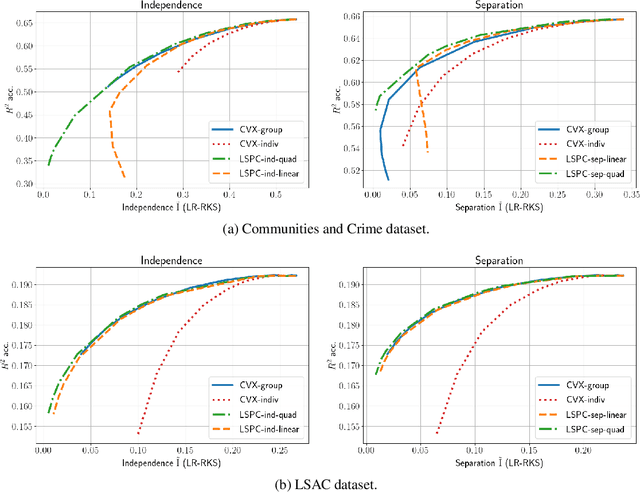
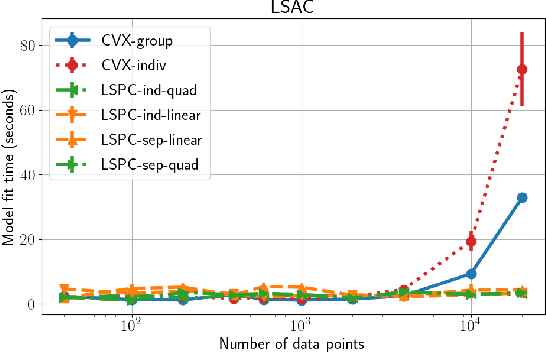
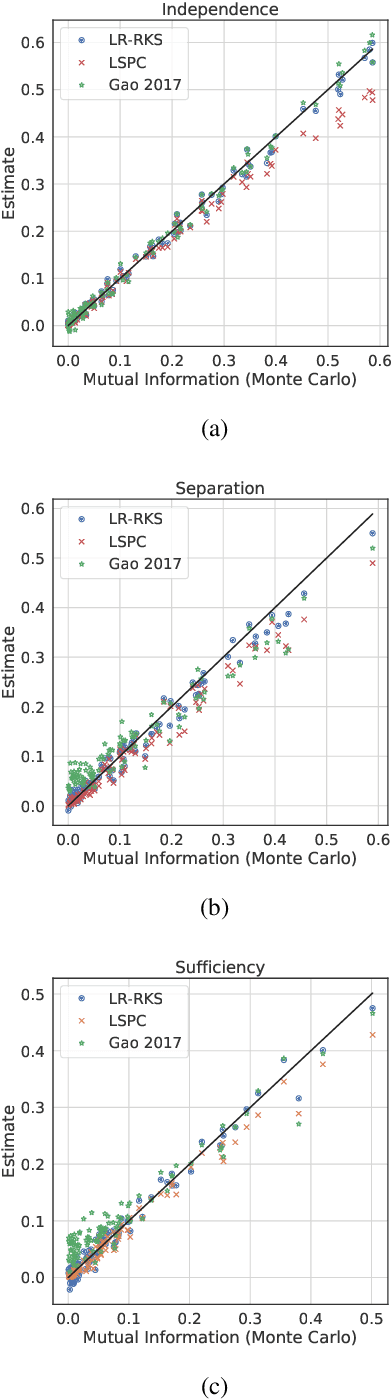
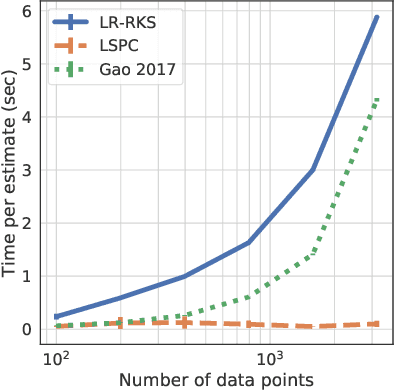
Most work in algorithmic fairness to date has focused on discrete outcomes, such as deciding whether to grant someone a loan or not. In these classification settings, group fairness criteria such as independence, separation and sufficiency can be measured directly by comparing rates of outcomes between subpopulations. Many important problems however require the prediction of a real-valued outcome, such as a risk score or insurance premium. In such regression settings, measuring group fairness criteria is computationally challenging, as it requires estimating information-theoretic divergences between conditional probability density functions. This paper introduces fast approximations of the independence, separation and sufficiency group fairness criteria for regression models from their (conditional) mutual information definitions, and uses such approximations as regularisers to enforce fairness within a regularised risk minimisation framework. Experiments in real-world datasets indicate that in spite of its superior computational efficiency our algorithm still displays state-of-the-art accuracy/fairness tradeoffs.