 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFast Extraction of Word Embedding from Q-contexts
Paper and Code

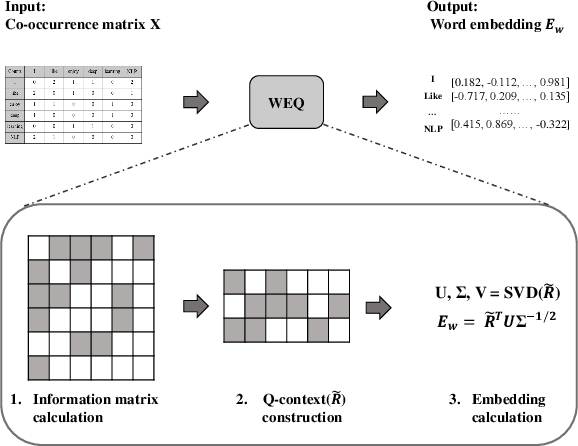
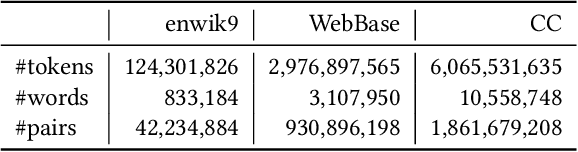
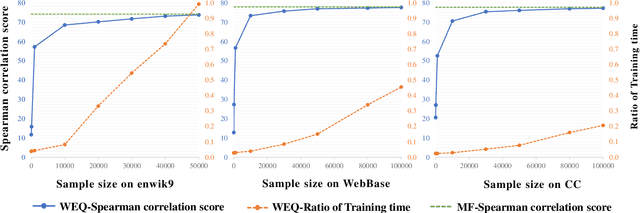
The notion of word embedding plays a fundamental role in natural language processing (NLP). However, pre-training word embedding for very large-scale vocabulary is computationally challenging for most existing methods. In this work, we show that with merely a small fraction of contexts (Q-contexts)which are typical in the whole corpus (and their mutual information with words), one can construct high-quality word embedding with negligible errors. Mutual information between contexts and words can be encoded canonically as a sampling state, thus, Q-contexts can be fast constructed. Furthermore, we present an efficient and effective WEQ method, which is capable of extracting word embedding directly from these typical contexts. In practical scenarios, our algorithm runs 11$\sim$13 times faster than well-established methods. By comparing with well-known methods such as matrix factorization, word2vec, GloVeand fasttext, we demonstrate that our method achieves comparable performance on a variety of downstream NLP tasks, and in the meanwhile maintains run-time and resource advantages over all these baselines.