 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFairness Based Energy-Efficient 3D Path Planning of a Portable Access Point: A Deep Reinforcement Learning Approach
Paper and Code
Aug 10, 2022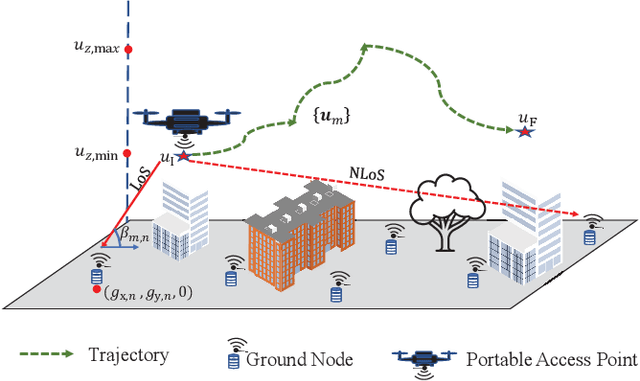
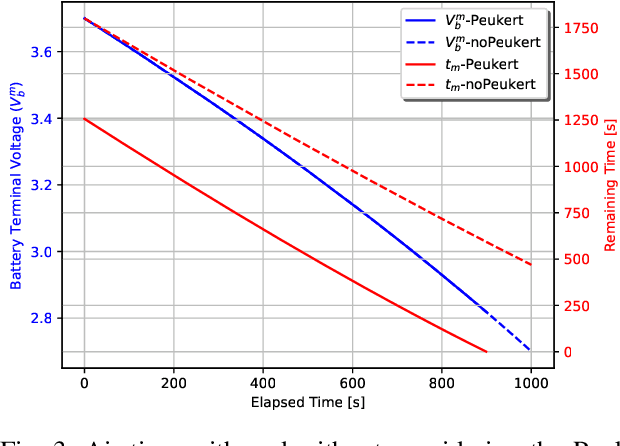
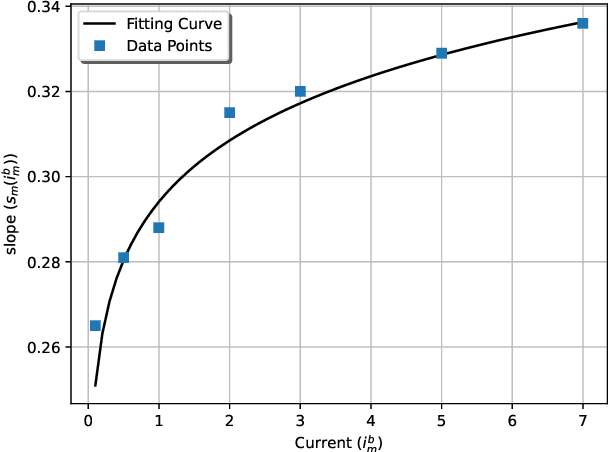
In this work, we optimize the 3D trajectory of an unmanned aerial vehicle (UAV)-based portable access point (PAP) that provides wireless services to a set of ground nodes (GNs). Moreover, as per the Peukert effect, we consider pragmatic non-linear battery discharge for the battery of the UAV. Thus, we formulate the problem in a novel manner that represents the maximization of a fairness-based energy efficiency metric and is named fair energy efficiency (FEE). The FEE metric defines a system that lays importance on both the per-user service fairness and the energy efficiency of the PAP. The formulated problem takes the form of a non-convex problem with non-tractable constraints. To obtain a solution, we represent the problem as a Markov Decision Process (MDP) with continuous state and action spaces. Considering the complexity of the solution space, we use the twin delayed deep deterministic policy gradient (TD3) actor-critic deep reinforcement learning (DRL) framework to learn a policy that maximizes the FEE of the system. We perform two types of RL training to exhibit the effectiveness of our approach: the first (offline) approach keeps the positions of the GNs the same throughout the training phase; the second approach generalizes the learned policy to any arrangement of GNs by changing the positions of GNs after each training episode. Numerical evaluations show that neglecting the Peukert effect overestimates the air-time of the PAP and can be addressed by optimally selecting the PAP's flying speed. Moreover, the user fairness, energy efficiency, and hence the FEE value of the system can be improved by efficiently moving the PAP above the GNs. As such, we notice massive FEE improvements over baseline scenarios of up to 88.31%, 272.34%, and 318.13% for suburban, urban, and dense urban environments, respectively.