 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFairness-aware Configuration of Machine Learning Libraries
Paper and Code
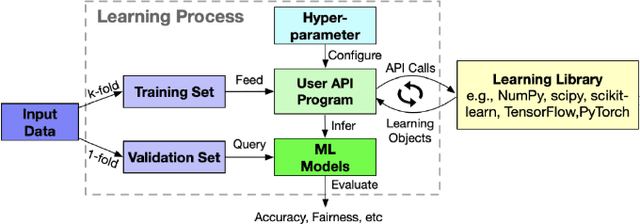


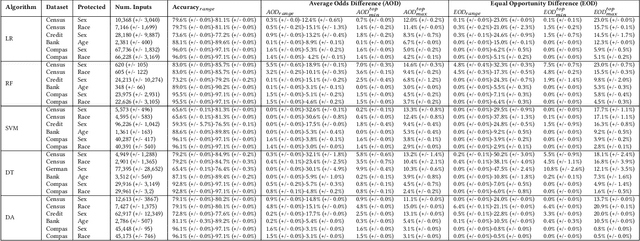
This paper investigates the parameter space of machine learning (ML) algorithms in aggravating or mitigating fairness bugs. Data-driven software is increasingly applied in social-critical applications where ensuring fairness is of paramount importance. The existing approaches focus on addressing fairness bugs by either modifying the input dataset or modifying the learning algorithms. On the other hand, the selection of hyperparameters, which provide finer controls of ML algorithms, may enable a less intrusive approach to influence the fairness. Can hyperparameters amplify or suppress discrimination present in the input dataset? How can we help programmers in detecting, understanding, and exploiting the role of hyperparameters to improve the fairness? We design three search-based software testing algorithms to uncover the precision-fairness frontier of the hyperparameter space. We complement these algorithms with statistical debugging to explain the role of these parameters in improving fairness. We implement the proposed approaches in the tool Parfait-ML (PARameter FAIrness Testing for ML Libraries) and show its effectiveness and utility over five mature ML algorithms as used in six social-critical applications. In these applications, our approach successfully identified hyperparameters that significantly improve (vis-a-vis the state-of-the-art techniques) the fairness without sacrificing precision. Surprisingly, for some algorithms (e.g., random forest), our approach showed that certain configuration of hyperparameters (e.g., restricting the search space of attributes) can amplify biases across applications. Upon further investigation, we found intuitive explanations of these phenomena, and the results corroborate similar observations from the literature.