 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgef-GANs in an Information Geometric Nutshell
Paper and Code
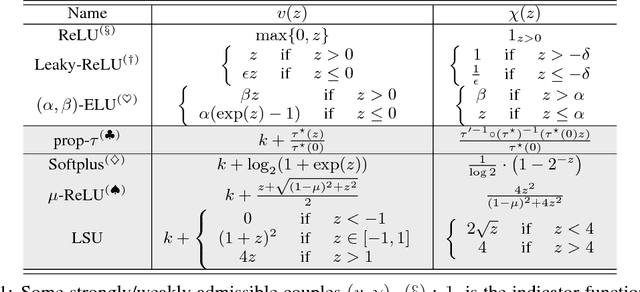
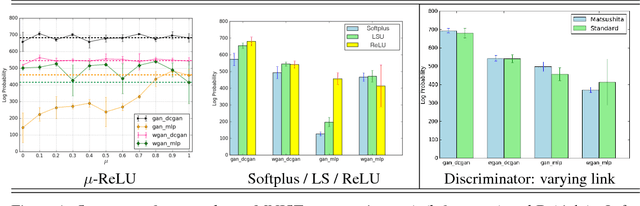
Nowozin \textit{et al} showed last year how to extend the GAN \textit{principle} to all $f$-divergences. The approach is elegant but falls short of a full description of the supervised game, and says little about the key player, the generator: for example, what does the generator actually converge to if solving the GAN game means convergence in some space of parameters? How does that provide hints on the generator's design and compare to the flourishing but almost exclusively experimental literature on the subject? In this paper, we unveil a broad class of distributions for which such convergence happens --- namely, deformed exponential families, a wide superset of exponential families --- and show tight connections with the three other key GAN parameters: loss, game and architecture. In particular, we show that current deep architectures are able to factorize a very large number of such densities using an especially compact design, hence displaying the power of deep architectures and their concinnity in the $f$-GAN game. This result holds given a sufficient condition on \textit{activation functions} --- which turns out to be satisfied by popular choices. The key to our results is a variational generalization of an old theorem that relates the KL divergence between regular exponential families and divergences between their natural parameters. We complete this picture with additional results and experimental insights on how these results may be used to ground further improvements of GAN architectures, via (i) a principled design of the activation functions in the generator and (ii) an explicit integration of proper composite losses' link function in the discriminator.