 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExposing Cross-Lingual Lexical Knowledge from Multilingual Sentence Encoders
Paper and Code
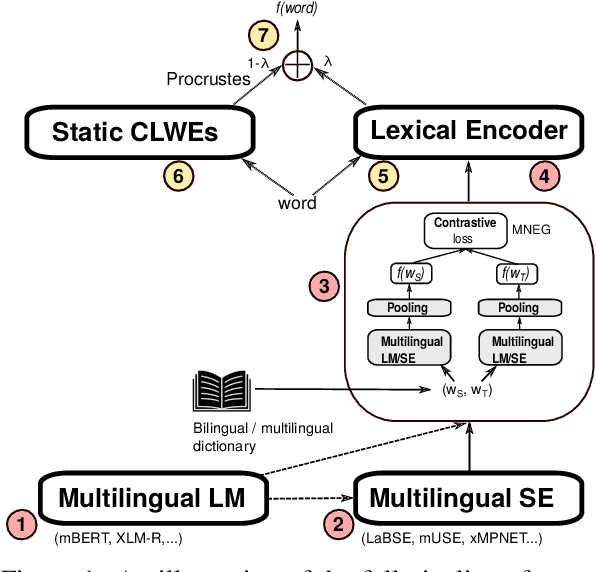
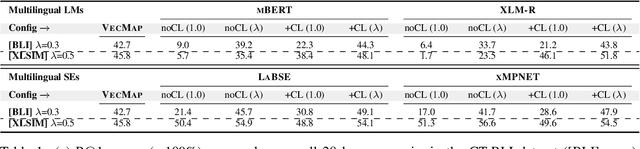
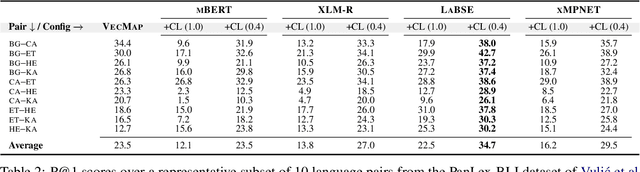

Pretrained multilingual language models (LMs) can be successfully transformed into multilingual sentence encoders (SEs; e.g., LaBSE, xMPNET) via additional fine-tuning or model distillation on parallel data. However, it remains uncertain how to best leverage their knowledge to represent sub-sentence lexical items (i.e., words and phrases) in cross-lingual lexical tasks. In this work, we probe these SEs for the amount of cross-lingual lexical knowledge stored in their parameters, and compare them against the original multilingual LMs. We also devise a novel method to expose this knowledge by additionally fine-tuning multilingual models through inexpensive contrastive learning procedure, requiring only a small amount of word translation pairs. We evaluate our method on bilingual lexical induction (BLI), cross-lingual lexical semantic similarity, and cross-lingual entity linking, and report substantial gains on standard benchmarks (e.g., +10 Precision@1 points in BLI), validating that the SEs such as LaBSE can be 'rewired' into effective cross-lingual lexical encoders. Moreover, we show that resulting representations can be successfully interpolated with static embeddings from cross-lingual word embedding spaces to further boost the performance in lexical tasks. In sum, our approach provides an effective tool for exposing and harnessing multilingual lexical knowledge 'hidden' in multilingual sentence encoders.