 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExponential Hardness of Reinforcement Learning with Linear Function Approximation
Paper and Code
Feb 25, 2023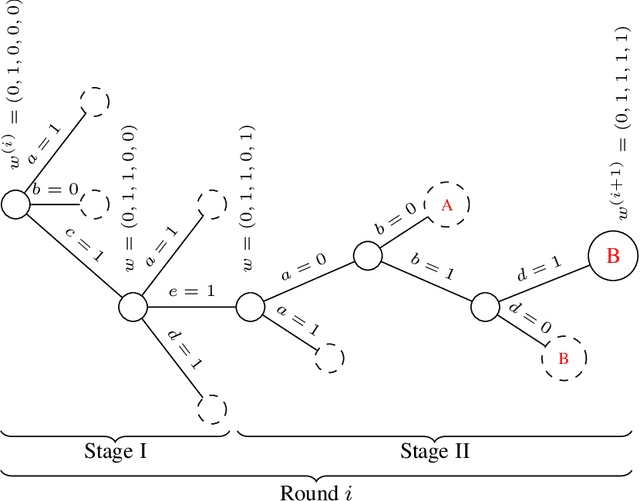
A fundamental question in reinforcement learning theory is: suppose the optimal value functions are linear in given features, can we learn them efficiently? This problem's counterpart in supervised learning, linear regression, can be solved both statistically and computationally efficiently. Therefore, it was quite surprising when a recent work \cite{kane2022computational} showed a computational-statistical gap for linear reinforcement learning: even though there are polynomial sample-complexity algorithms, unless NP = RP, there are no polynomial time algorithms for this setting. In this work, we build on their result to show a computational lower bound, which is exponential in feature dimension and horizon, for linear reinforcement learning under the Randomized Exponential Time Hypothesis. To prove this we build a round-based game where in each round the learner is searching for an unknown vector in a unit hypercube. The rewards in this game are chosen such that if the learner achieves large reward, then the learner's actions can be used to simulate solving a variant of 3-SAT, where (a) each variable shows up in a bounded number of clauses (b) if an instance has no solutions then it also has no solutions that satisfy more than (1-$\epsilon$)-fraction of clauses. We use standard reductions to show this 3-SAT variant is approximately as hard as 3-SAT. Finally, we also show a lower bound optimized for horizon dependence that almost matches the best known upper bound of $\exp(\sqrt{H})$.