 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Demonstration Ensembling for In-context Learning
Paper and Code

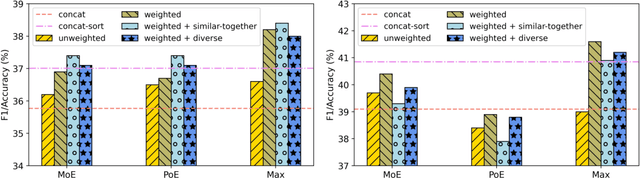
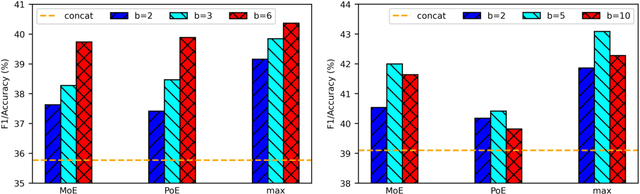
In-context learning (ICL) operates by showing language models (LMs) examples of input-output pairs for a given task, i.e., demonstrations. The standard approach for ICL is to prompt the LM with concatenated demonstrations followed by the test input. This approach suffers from some issues. First, concatenation offers almost no control over the contribution of each demo to the model prediction. This can be sub-optimal when some demonstrations are irrelevant to the test example. Second, due to the input length limit of some transformer models, it might be infeasible to fit many examples into the context, especially when dealing with long-input tasks. In this work, we explore Demonstration Ensembling (DENSE) as an alternative to simple concatenation. DENSE predicts outputs using subsets (i.e., buckets) of the demonstrations and then combines the output probabilities resulting from each subset to produce the final prediction. We study different ensembling methods using GPT-j and experiment on 12 language tasks. Our experiments show weighted max ensembling to outperform vanilla concatenation by as large as 2.4 average points. Code available at https://github.com/mukhal/icl-ensembling.