 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploiting Syntactic Structure for Better Language Modeling: A Syntactic Distance Approach
Paper and Code
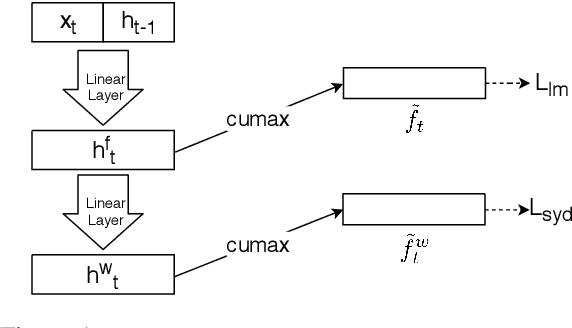



It is commonly believed that knowledge of syntactic structure should improve language modeling. However, effectively and computationally efficiently incorporating syntactic structure into neural language models has been a challenging topic. In this paper, we make use of a multi-task objective, i.e., the models simultaneously predict words as well as ground truth parse trees in a form called "syntactic distances", where information between these two separate objectives shares the same intermediate representation. Experimental results on the Penn Treebank and Chinese Treebank datasets show that when ground truth parse trees are provided as additional training signals, the model is able to achieve lower perplexity and induce trees with better quality.