 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploiting Neural Query Translation into Cross Lingual Information Retrieval
Paper and Code
Oct 26, 2020

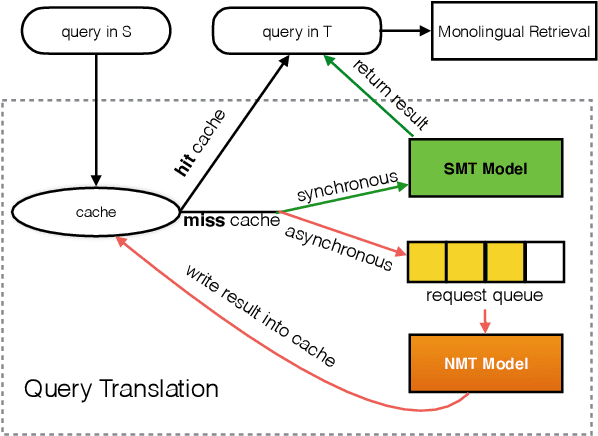

As a crucial role in cross-language information retrieval (CLIR), query translation has three main challenges: 1) the adequacy of translation; 2) the lack of in-domain parallel training data; and 3) the requisite of low latency. To this end, existing CLIR systems mainly exploit statistical-based machine translation (SMT) rather than the advanced neural machine translation (NMT), limiting the further improvements on both translation and retrieval quality. In this paper, we investigate how to exploit neural query translation model into CLIR system. Specifically, we propose a novel data augmentation method that extracts query translation pairs according to user clickthrough data, thus to alleviate the problem of domain-adaptation in NMT. Then, we introduce an asynchronous strategy which is able to leverage the advantages of the real-time in SMT and the veracity in NMT. Experimental results reveal that the proposed approach yields better retrieval quality than strong baselines and can be well applied into a real-world CLIR system, i.e. Aliexpress e-Commerce search engine. Readers can examine and test their cases on our website: https://aliexpress.com .