 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExact Gaussian Processes on a Million Data Points
Paper and Code
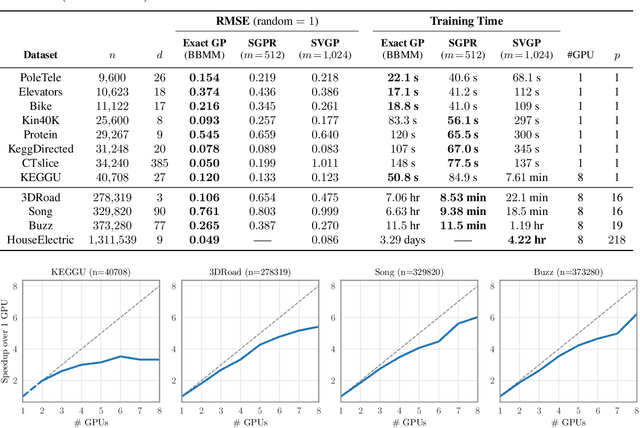

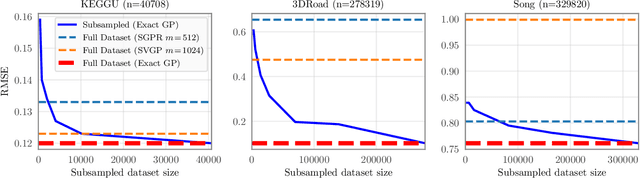

Gaussian processes (GPs) are flexible models with state-of-the-art performance on many impactful applications. However, computational constraints with standard inference procedures have limited exact GPs to problems with fewer than about ten thousand training points, necessitating approximations for larger datasets. In this paper, we develop a scalable approach for exact GPs that leverages multi-GPU parallelization and methods like linear conjugate gradients, accessing the kernel matrix only through matrix multiplication. By partitioning and distributing kernel matrix multiplies, we demonstrate that an exact GP can be trained on over a million points in 3 days using 8 GPUs and can compute predictive means and variances in under a second using 1 GPU at test time. Moreover, we perform the first-ever comparison of exact GPs against state-of-the-art scalable approximations on large-scale regression datasets with $10^4-10^6$ data points, showing dramatic performance improvements.