 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvidence Sentence Extraction for Machine Reading Comprehension
Paper and Code

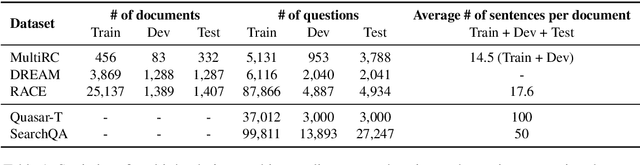
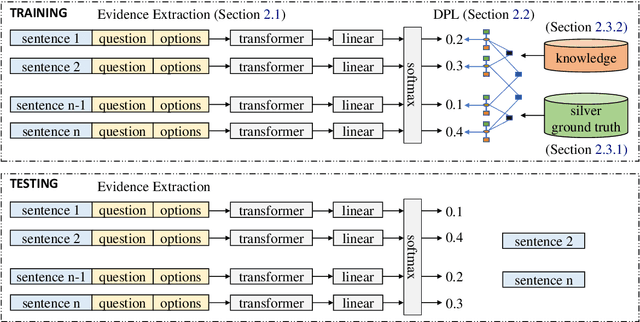
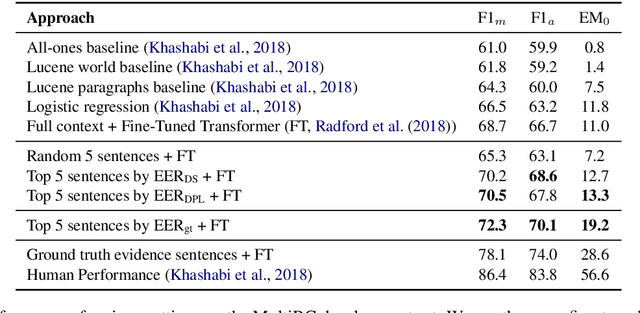
Recently remarkable success has been achieved in machine reading comprehension (MRC). However, it is still difficult to interpret the predictions of existing MRC models. In this paper, we focus on: extracting evidence sentences that can explain/support answer predictions for multiple-choice MRC tasks, where the majority of answer options cannot be directly extracted from reference documents; studying the impacts of using the extracted sentences as the input of MRC models. Due to the lack of ground truth evidence sentence labels in most cases, we apply distant supervision to generate imperfect labels and then use them to train a neural evidence extractor. To denoise the noisy labels, we treat labels as latent variables and define priors over these latent variables by incorporating rich linguistic knowledge under a recently proposed deep probabilistic logic learning framework. We feed the extracted evidence sentences into existing MRC models and evaluate the end-to-end performance on three challenging multiple-choice MRC datasets: MultiRC, DREAM, and RACE, achieving comparable or better performance than the same models that take the full context as input. Our evidence extractor also outperforms a state-of-the-art sentence selector by a large margin on two open-domain question answering datasets: Quasar-T and SearchQA. To the best of our knowledge, this is the first work addressing evidence sentence extraction for multiple-choice MRC.