 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEscaping Saddle-Points Faster under Interpolation-like Conditions
Paper and Code
Sep 28, 2020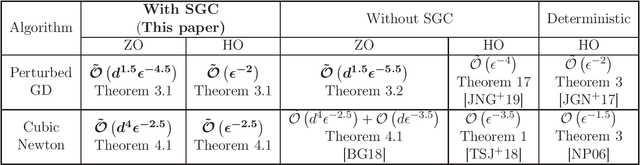
In this paper, we show that under over-parametrization several standard stochastic optimization algorithms escape saddle-points and converge to local-minimizers much faster. One of the fundamental aspects of over-parametrized models is that they are capable of interpolating the training data. We show that, under interpolation-like assumptions satisfied by the stochastic gradients in an over-parametrization setting, the first-order oracle complexity of Perturbed Stochastic Gradient Descent (PSGD) algorithm to reach an $\epsilon$-local-minimizer, matches the corresponding deterministic rate of $\tilde{\mathcal{O}}(1/\epsilon^{2})$. We next analyze Stochastic Cubic-Regularized Newton (SCRN) algorithm under interpolation-like conditions, and show that the oracle complexity to reach an $\epsilon$-local-minimizer under interpolation-like conditions, is $\tilde{\mathcal{O}}(1/\epsilon^{2.5})$. While this obtained complexity is better than the corresponding complexity of either PSGD, or SCRN without interpolation-like assumptions, it does not match the rate of $\tilde{\mathcal{O}}(1/\epsilon^{1.5})$ corresponding to deterministic Cubic-Regularized Newton method. It seems further Hessian-based interpolation-like assumptions are necessary to bridge this gap. We also discuss the corresponding improved complexities in the zeroth-order settings.